

Social GPT Chrome Extension
Social GPT Chrome Extension是一款无需注册即可用的AI社交写作与互动助手插件,支持多语言、免费且隐私友好,极大简化社交媒体内容创作与交流。
Luminal is a one-stop AI model inference acceleration and big data processing platform that enables automatic model optimization and rapid deployment, while also supporting automatic cleaning and analysis of structured data such as tables.
Luminal A new generationAI model inference acceleration and data processingThe platform supports the rapid deployment and efficient operation of mainstream AI framework models on various hardware platforms. Through automated compilation and serverless deployment, it significantly reduces the operational burden on developers and enterprises, making it an innovative tool for improving AI efficiency. The platform also integrates AI-powered cleaning and processing capabilities for large-scale structured data and tables, making it ideal for research and commercial applications.
In today's era of flourishing AI technology,Luminal With its sophisticated AI model acceleration and large-scale data processing capabilities, it has become a focus of attention for many developers and enterprises. From helping research teams efficiently deploy models to enterprise-level massive data cleaning and analysis,Luminal Luminal is reshaping AI development and deployment processes with innovative thinking. This article, presented in a news report format, will provide an in-depth analysis of the platform's core functions, applicable scenarios, user experience, and pricing strategy. It will also offer a comprehensive perspective for AI practitioners, developers, and data engineers by combining official and publicly available information.
Official website:https://getluminal.com
Luminal Its core mission is to "enable AI models to run at extremely high speeds on any hardware." Through its self-developed ML compiler and CUDA kernel automatic generation technology, it converts AI models under mainstream frameworks such as PyTorch into code highly optimized for GPUs, achieving more than 10 times the inference speed and greatly reducing hardware and cloud computing costs.
| Functional categories | Detailed description |
|---|---|
| Model optimization | It automatically analyzes the model operator structure and generates optimal GPU kernel code, without relying on manual optimization. |
| Extreme acceleration | Comparable to advanced kernels such as handwriting Flash Attention, achieving industry-leading inference speed. |
| Automated deployment | Serverless inference only requires uploading the weights to obtain the API endpoint. |
| Intelligent cold start | Compiler caching and parameter streaming significantly reduce cold start latency and eliminate resource idle costs. |
| Automatic batch processing | Dynamically merge requests to fully utilize GPU computing power and achieve elastic load scaling. |
| Platform compatibility | Compatible with mainstream cloud services and local GPUs, supports Huggingface and PyTorch frameworks. |

The official website provides detailed performance benchmark data, demonstrating its significant advantages over traditional inference solutions in production environments.
Luminal is currently awaiting the roster (W)aiThe billing model (tlist) is mainly divided into two categories: pay-as-you-go and enterprise customization.Serverless InferenceThe AI efficiency improvement payment model only charges for actual inference API calls, with no GPU idle fees, greatly reducing enterprise expenses.
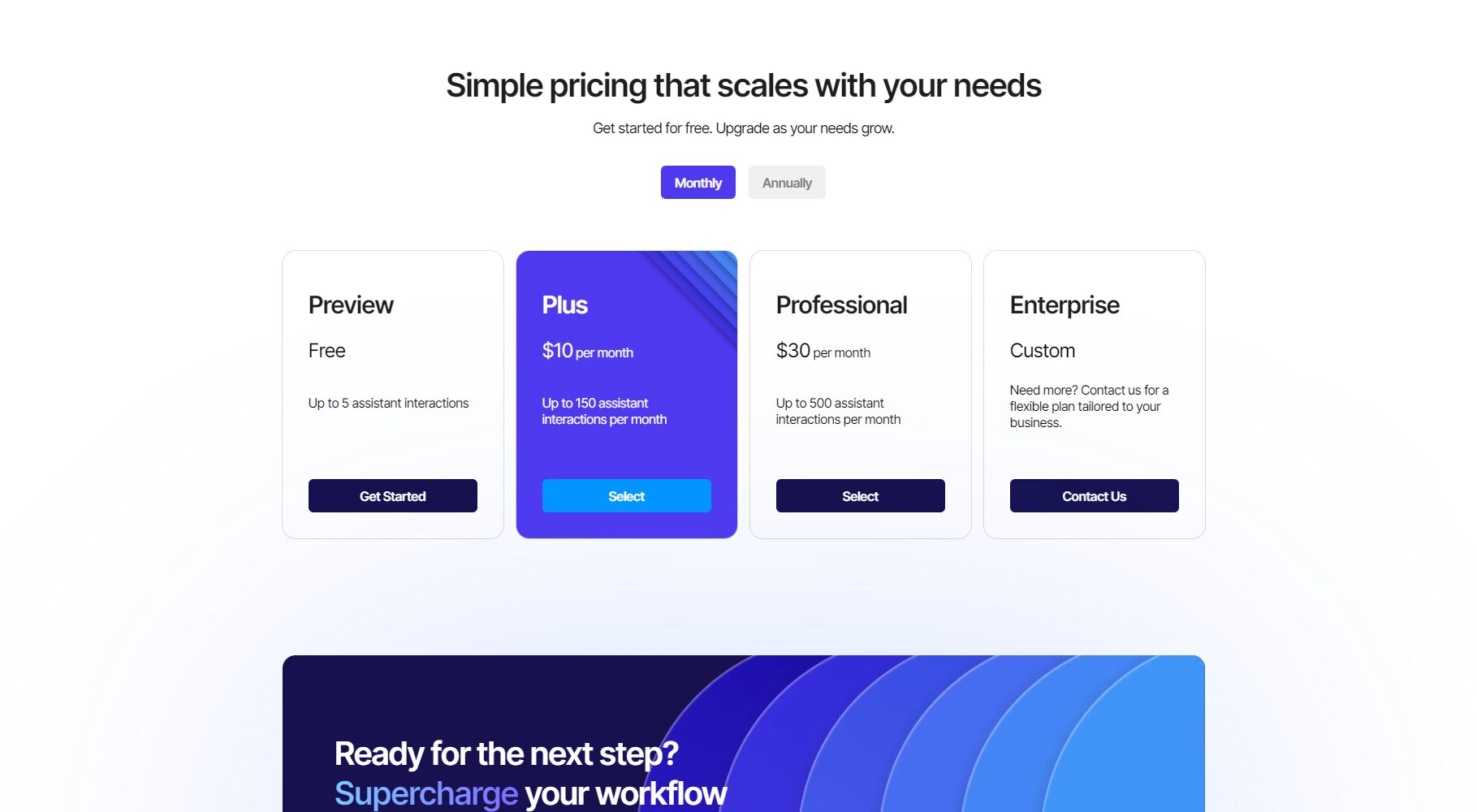
| Scheme type | Applicable to | Billing method | Core Features | How to obtain |
|---|---|---|---|---|
| Individual/Developer | Academic/Personal Research and Development | Billing based on usage | Free quota + charges apply for exceeding quota, quick deployment. | Join Waitlist |
| Enterprise/Research Team | Enterprises/Institutions | Tiered usage + package | Customized services, private cloud support | Contact Team |
| Open source local experience | Developers/Academics | Free/Open Source | Build your own trial version; community support available. | GitHub |
Luminal features a minimalist design that integrates AI model acceleration with automated deployment processes.
# pseudocode demonstration import luminal model = luminal.load('your_model.pt') endpoint = luminal.deploy(model) result = endpoint.predict(input_data)
This greatly reduces the barriers to engineering deployment and maintenance! For more development documentation, please see Luminal GitHub project。
| Industry Scenarios | Application Description |
|---|---|
| Financial risk control | Dynamic deployment of automated risk control models and support for high-concurrency inference. |
| Biomedical | Real-time processing and big data analysis of medical diagnosis |
| Intelligent Customer Service | Rapid Upgrade of NLU Model for Large Customer Service Centers |
| e-commerce | Elastic scaling of product retrieval/personalized recommendation models |
| Research institutions | Experimental model release and replication experiments drive industrial transformation |
In addition to AI model inference, Luminal also focuses on data processing. For example, the platform has [specific features] for structured data and large spreadsheets.AI-powered automatic cleaning, conversion, and analysis.ability:
Luminal's founding members previouslyIntel, Amazon, AppleThe company is leading the development of AI operator optimization and compilers, and has received support from top incubator Y Combinator. The platform's vision is to free up AI teams from hardware tuning concerns, allowing them to focus more on algorithm innovation and business implementation, thereby accelerating the popularization and industrialization of AI.
The platform employs automatic operator analysis and high-level hardware abstraction, is compatible with mainstream PyTorch and Huggingface frameworks, and its CUDA code is adapted to various mainstream GPUs/cloud services, making it suitable for future computing power upgrades.
Luminal utilizes intelligent caching and streaming weighted loading to reduce cold start latency to extremely low levels, eliminates the need to pay for idle GPUs, and allows for elastic scaling of resources.
Developers can apply for a trial through the official website's waitlist, while companies can directly contact the Luminal team via email to customize services.
As a leader in AI inference and efficient data processing, Luminal is driving a new paradigm of "ready-to-use on the cloud" AI models, characterized by simplicity and efficiency. Whether you are an AI innovator, a corporate data manager, or looking to reduce costs and increase efficiency for your development team, Luminal is undoubtedly worth your continued attention and exploration. In the future, with the increasing complexity of models and the democratization of computing power, Luminal will further unleash AI productivity, bringing more possibilities to the industry.Click to learn more about Luminal.
This site's AI-powered navigation is provided by Miao.LuminalAll external links originate from the internet, and their accuracy and completeness are not guaranteed. Furthermore, AI Miao Navigation does not have actual control over the content of these external links. As of 10:14 PM on November 15, 2025, the content on this webpage was compliant and legal. If any content on the webpage becomes illegal in the future, you can directly contact the website administrator for deletion. AI Miao Navigation assumes no responsibility.
