What is mode collapse? How to effectively avoid mode collapse in generative AI (including practical solutions)
mode collapse(模式崩溃)是Generative AIA common and far-reaching problem in training is the output's lack of diversity and uniformity, resulting in the omission of rare or unique information from the data distribution. This paper not only analyzes the causes of mode collapse in detail but also summarizes systematic solutions, including...Several practical methods including data management, algorithm optimization, model monitoring, and combining synthetic and original data.,帮助AI开发与运营团队有效应对模式崩溃风险,保障生成式AI的Innovation and diversity。

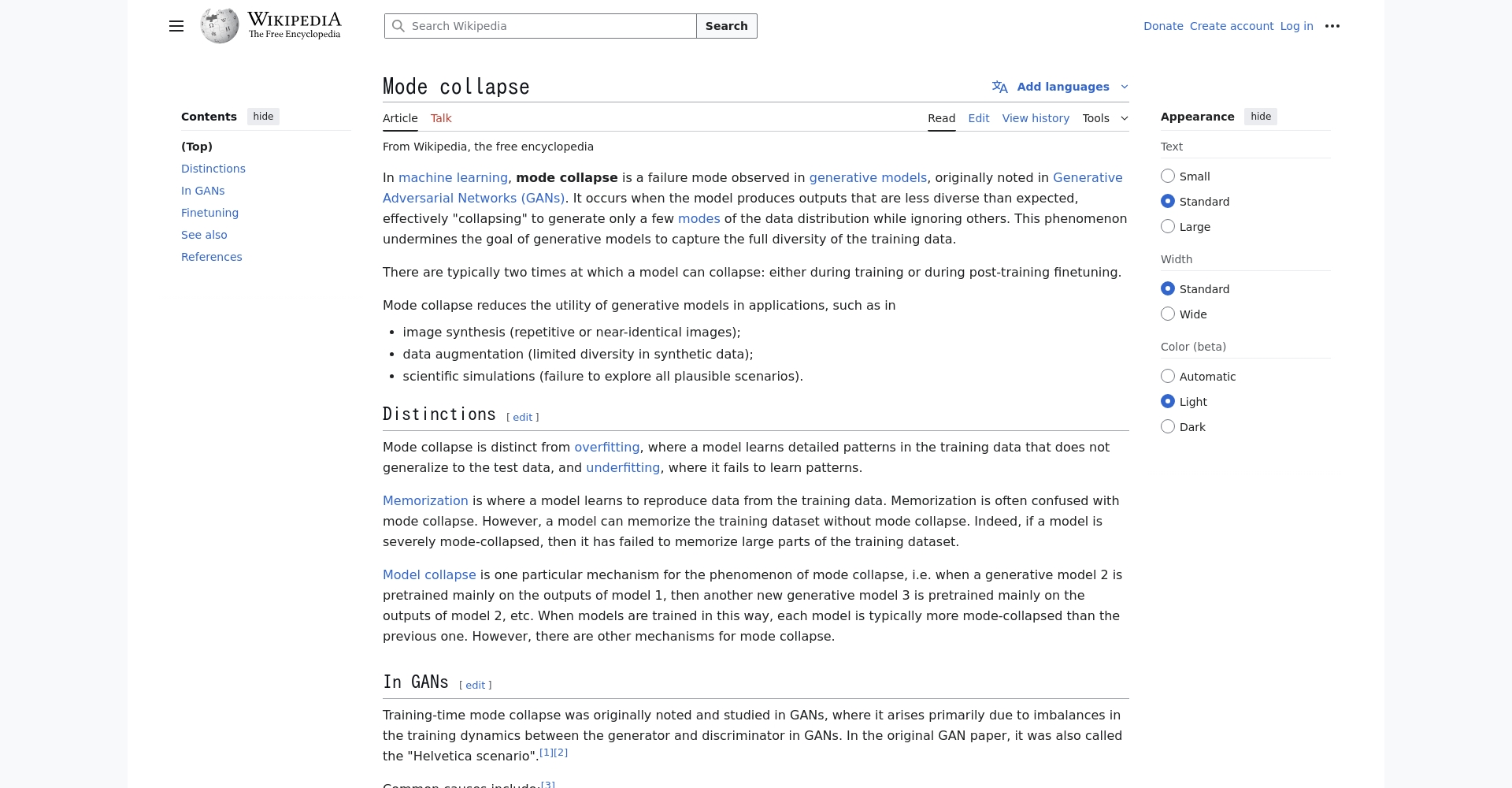
Analysis of the mode collapse phenomenon
What is mode collapse?
mode collapseThis refers to generative artificial intelligence (AI) models, such as GAN (Generative Adversarial Network), VAE (Variational Autoencoder), and Large Language Model (LLM), which, when generating data, produce outputs that are singular and lack diversity, focusing only on a few "patterns" in the data distribution, thus forgetting the rarer and more diverse information in the original data.
This problem was first discovered during the training of GANs. For example, once a GAN generator learns to deceive the discriminator, it may only output a single category (such as always black and white shoes), ignoring other sample types that exist in the real distribution, which greatly affects the richness of the generated content and its practical application.
Consequences of mode collapse
- The diversity of generated content has been greatly reduced.The output type no longer covers all data distributions.
- Rare information and long-tail knowledge are forgotten.AI ignores a few patterns and only remembers common content.
- Recommendation systems, dialogues, and personalized services have declined significantly: they are unable to meet professional and personalized needs.
- It affects the fair and equitable development of innovation in the fields of science, medicine, and knowledge.
| Model type | mode collapse manifestations | Typical impact |
|---|---|---|
| GAN/Image Generation | Output images with extremely similar appearances | Loss of creativity in visual elements |
| LLM/Text Generation | The sentence structure and topic are highly repetitive. | The dialogue was stiff and lacked detail. |
| Recommendation system | Only mainstream products are promoted, while niche products are ignored. | Monotonous user experience and churn |
| Medical AI | Ignoring rare diseases and special samples | A one-sided diagnosis can even be life-threatening. |

Why does a mode crash occur? Analysis of the causes.
Factors during the training process
- Discriminator and generator imbalance (e.g., GAN)The difference in training progress between the two sides causes the generator to output only a few patterns to confuse the discriminator.
- Inadequate design of loss functionFor example, Jensen-Shannon divergence discourages diverse outputs and makes it difficult to capture long tails.
- Narrow or imbalanced training set distributionWith limited data or training only with regenerated data, the model gradually loses its diversity.
- Multigenerational self-circulation trainingThe new model is only based on the previous generation of AI data, which amplifies its own shortcomings.
Data Sources and Fine-Tuning Pitfalls
- The proportion of synthetic data is too highThe content is limited, and true diversity is lost after accumulating feedback.
- Defects of the Human Feedback Reward Model (RLHF)The model only learns to conform to reward criteria, rather than true diversity.
Model mechanism related
- The discriminator struggles to distinguish between outputs with low diversity.
- Overemphasizing mainstream and high-frequency features while neglecting long-tail content.
Identification and monitoring of mode collapse
- The generated samples are generally the same or repetitiveFor example, the images are almost identical, and the text language is highly mechanical.
- Ignore marginal categories or obscure information
- Adaptability deteriorates significantly under new domain tasks.
- Scientific statistical methods can be used for detection, such as component entropy, diversity coverage, and similarity index.
Practical solutions to effectively avoid mode collapse
| Solution Types | Method Introduction | Recommended tools/cases |
|---|---|---|
| Data Management | Retain and supplement authentic original data | IBM watsonx.governance™ |
| Data collection and traceability | Tracking the source of training samples | Data Provenance Initiative |
| Algorithm-level optimization | Improved loss function and regularization | Wasserstein GAN, etc. |
| Increased diversity in training processes | Batch discrimination technology | OpenAI GAN Technology White Paper |
| Synthetic data quality assurance | High-quality synthesis + real data blend | Synthesis AI |
| IT governance and monitoring | Automated monitoring and feedback | IBM watsonx.governance™ |
Data strategy optimization method
- Continuously introduce high-quality original human dataWe refuse to rely solely on synthesized content and regularly refresh the model to retain long-tail capabilities.
- Strict data traceability and labelingTracking the source and time of data collection facilitates subsequent filtering and diversity retraining.
- Generational cumulative hybrid trainingWe use a mixture of real and multi-generational synthetic data for training to enhance generalization.
Algorithm engineering optimization method (taking GAN/image as an example)
- mini-batch discriminationThe discriminator examines the diversity of a set of samples simultaneously.
- Unrolled GAN, Two-Time Scale Update: Optimize the generator's foresight regarding the discriminator's strategy to avoid short-sighted convergence.
- Wasserstein GAN/EM distance: Enhance diversity by using a more robust distance metric.
- Expand training set diversity and sampling coverage
Language/Large Model Class Methods
- Multi-objective optimization and structured rewardsIntroduce diverse rewards in reinforcement learning fine-tuning (such as RLHF).
- To prevent overfitting during fine-tuning, freeze parameters appropriately.It retains the diverse expressive capabilities of the original pre-training stage.
Data governance and monitoring practices
- Introduce AI governance tools (such as IBM watsonx.governance™) to automatically monitor and provide feedback to correct anomalies.
- Establish a long-term offline evaluation set to examine the changes in the model's performance on niche and long-tail tasks.
Training by combining synthetic and human data
- Improve the quality of synthetic content algorithms (third-party high-standard synthetic data platforms can be adopted in fields such as medicine, remote sensing, and industry).
- By combining human-created data with AI data as needed, we can avoid the "self-circulation" trap.
Future Outlook and Development Trends
As AI-generated content gradually dominates the content ecosystem, the problem of model collapse becomes more prominent.In the future, AI developers need to take a holistic approach, focusing on data, algorithms, and regulation, continuously investing in data diversity, optimizing model mechanisms, and introducing sustainable governance systems to truly achieve innovation, diversity, and fairness in AI. Only by acknowledging and overcoming mode collapse can we ensure that generative AI continues to empower technological innovation and social progress!
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.
Related posts

No comments...