本文解析了「蝴蝶效應」在AI決策領域中的實際影響,透過醫療、金融與內容審核三大領域案例,揭示了微小輸入變動如何引發模型輸出巨變,可能帶來的風險及相應的規避建議。
介紹了蝴蝶效應的定義,並梳理AI系統為何對此如此敏感,從資料規格、模型可解釋性、穩健性測試等角度,給予系統性的防範方法與操作建議。幫助企業和開發者全面理解此現象,並提出有效防範對策。
什麼是「蝴蝶效應」及其在AI決策中的作用?
“蝴蝶效應”,源自混沌理論,形容系統中微小的初始變化能帶來巨大的結果差異。在AI領域,這意味著一個看似微不足道的輸入變動,可能導致AI模型輸出完全不同的結論。隨著AI工具(如OpenAI ChatGPT、Google Gemini)廣泛應用於醫療、金融、交通等多個決策領域,複雜演算法背後的「蝴蝶效應」也愈發引人關注。
蝴蝶效應影響AI決策的實際案例解析
案例一:醫療診斷系統中的細微資料擾動
在2019年的一項知名醫學AI研究中,研究人員發現,醫療影像AI輔助診斷系統僅因像素級的微小變動,診斷結果可大幅波動。
例如,在胸部X光影像中加入極其輕微的噪聲,就可能導致AI將本來健康的病人錯誤診斷為肺部異常。

- 對病人安全構成威脅:誤診可能造成誤治、拖延治療。
- 醫療責任歸屬難以釐清:醫師是否可以信賴AI工具的每一個細節?
相關AI工具:IBM Watson Health、Google Cloud Healthcare AI
| 微小變化 | 資料預處理方式 | 診斷結果差異 |
|---|---|---|
| X光像素增減1% | 影像歸一處理 | 正常→疑似結節 |
| 病人資訊拼字錯誤 | 詞嵌入編碼 | 無風險→高風險(如吸菸史) |
| 隨機噪音注入 | 影像增強演算法 | 暫無病變→疑似異常 |
案例二:金融信用評分中的輸入波動
世界各大金融機構依賴AI模型進行信貸評級和審批。
根據麻省理工學院(MIT)2022年的報告,信貸AI只要輸入特徵中某項資料(如職業描述)進行細微編輯(如增加或減少一個字),就可能引發模型信用得分大幅波動。
- 客戶權益受損:風險評估過高導致貸款被拒絕或利率上升。
- 合規風險:難以追蹤AI決策邏輯,不利於金融監理。
相關AI工具:FICO Score AI系統、Zest AI信貸決策
| 輸入變化 | 模型處理機制 | 信用評等波動 |
|---|---|---|
| 職業由“教師”到“初中教師” | 詞嵌入及職業匹配 | 評分下調3分 |
| 地址拼字格式變化 | 地域風險權重 | 部分區域利率上調 |
| 月收入輸入括號 | 字串標準化失敗 | 薪資識別為異常停止審核 |
案例三:輿情分析與內容審核的陳述細微調整
在內容審核與網路輿情監測領域,AI模型需快速判斷內容是否違規。
根據騰訊優圖實驗室2023年的測試,僅一個標點或表述順序的調整,模型對同一資訊的違規預測機率就可能相差15%以上。
- 平台誤判、誤封帳號:正常用戶受到不公平處罰。
- 虛假輿論擴散防控漏洞:惡意操作者利用AI機制漏洞繞過偵測。
相關AI工具:騰訊優圖NLP內容審核、百度內容安全API
| 文字變動 | 審核模型回應 | 結論差異 |
|---|---|---|
| “這是非法集會!” | 判定為違規 | 內容封禁 |
| “「非法集會吧?」(加問號) | 判定為不違規 | 內容透過 |
| 句子拆分次序調整 | 輿情情感分數大幅變化 | 熱點監控優先權調整 |
AI決策中蝴蝶效應的技術成因與風險
為什麼AI模型對「蝴蝶效應」如此敏感?
- 深度神經網路的非線性:小輸入可透過多層疊加,放大為輸出的大波動。
- 黑箱模型不可解釋性:難以追蹤內部決策鏈路,增加了不可預知性。
- 數據分佈脆弱:訓練資料中的偏差、小樣本極易造成模型對微小變化過敏。
- 輸入規範化標準不一:不同系統輸入預處理細節差異,導致輸出差異。
| 風險類別 | 潛在後果 | 影響領域 |
|---|---|---|
| 誤判/漏判 | 損失公信力、法律爭議 | 金融、司法、內容審核 |
| 難以追責 | 監管盲點、用戶投訴 | 所有自動決策型應用 |
| 操縱利用漏洞 | 被黑灰產或競爭對手利用 | 輿情、金融、廣告投放 |
| 信任下滑 | 客戶轉向傳統人工複查 | 醫療、智慧問答、教育等 |
如何規避或降低AI決策中蝴蝶效應的風險?
明確輸入輸出格式與資料規範
- 透過嚴格輸入範本、欄位校驗,減少非結構化輸入變異。
- 應用如OpenAI Function Calling等功能,規範API介面呼叫輸入輸出。
多模型交叉驗證與解釋性增強
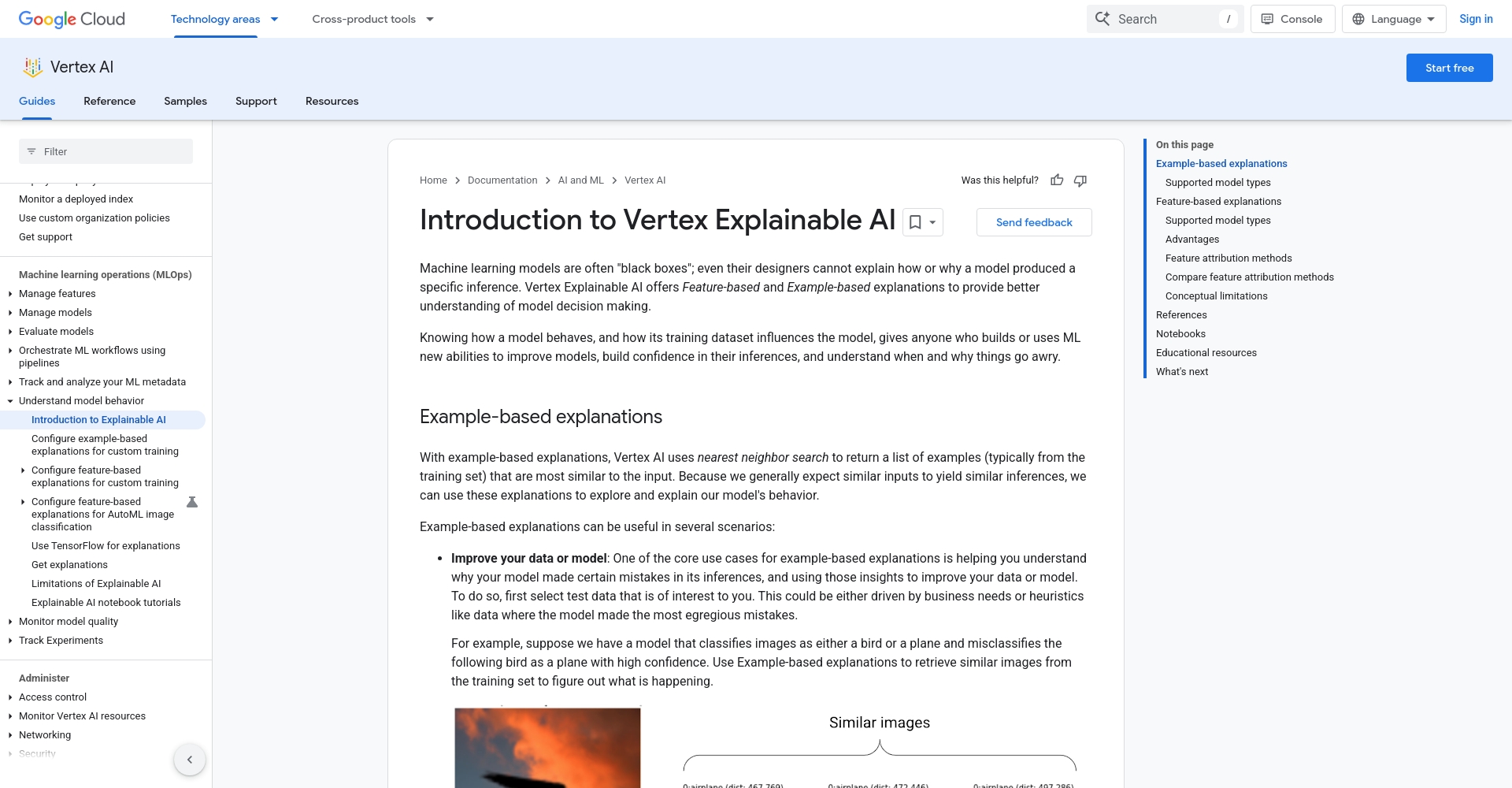
- 可結合Google Explainable AI等服務,透過解釋器顯示模型為何做出某決定,以便及時發現並校正異常響應。

圖/可解釋人工智慧展示 - 增設“複核模型”,對關鍵結果進行人工或其他模型的交叉複核。
增強對抗性穩健性測試
- 利用如IBM Adversarial Robustness Toolbox等開源工具,定期對AI模型實施擾動測試,找出敏感輸入點。
| 措施 | 說明 |
|---|---|
| 多樣化輸入情形測試 | 測試極端和邊界案例,完善資料覆蓋 |
| 明確規範與模板 | 所有輸入輸出強制要求範本、核准規範 |
| 加強模型解釋與透明度 | 推廣可解釋AI、回饋機制 |
| 雙重系統/多重判定機制 | 重要決策用不同演算法/模型複核 |
| 持續風險監控與日誌追蹤 | 對每次決策過程詳細記錄,方便追溯與優化 |
| 制定異常自報/人工介入機制 | 發現異常時手動介入,及時補救 |
| 定期更新與對抗性訓練 | 持續優化模型對「蝴蝶效應」式乾擾的穩健性 |
在這個由AI驅動的時代,蝴蝶效應在自動決策領域的影響不容小覷。
只要輸入一個停頓、一處拼字錯誤、一個不經意的格式變動,系統判斷就可能天差地別。企業與開發者只有透過嚴格資料管理、多重驗證與風險監控手段,才能真正駕馭AI,防止微小變動演變為決策災難。隨著科技進步,理解與預防數位世界的「蝴蝶效應」將成為AI落地應用的新常態。
© 版權聲明
文章版權歸作者所有,未經允許請勿轉載。
相關文章

暫無評論...