
高斯分佈(又稱常態分佈)是統計學和資料科學領域最基礎且廣泛應用的機率模型,其「鐘型曲線」描述了眾多自然現象與社會資料的分佈規律。本文以新聞深度報導角度,系統解析高斯分佈的基本原理、數學公式、經典應用場景與產業誤區,並結合專家觀點與實際案例,幫助你全面掌握高斯分佈在當今AI、金融、工業中的核心價值。
高斯分佈基本概念與公式推導
高斯分佈是什麼?定義與特徵
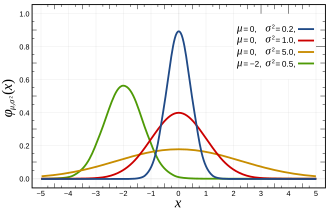
高斯分佈,又稱「常態分佈」(Normal Distribution),是機率論和統計學中極為重要的連續型分佈,其機率密度函數呈標準「“鐘型曲線”,左右對稱,均值處取最大機率。命名來自德國數學家卡爾·弗里德里希·高斯。
| 分佈類型 | 參數 | 曲線形狀 | 代表意義 |
|---|---|---|---|
| 高斯分佈/常態分佈 | 均值μ、標準差σ | 鐘型對稱 | 多種自然與社會現象的數學模型 |
數學歷程:機率密度函數推導
一維高斯分佈(常態分佈)的機率密度函數為:
$ f(x) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left( -\frac{(x-\mu)^2}{2\sigma^2} \right) $
- μ(均值):決定分佈的中心。
- σ(標準差):決定分佈寬窄,σ越小曲線越高越窄,σ越大越平。
當μ=0、σ=1時,稱為標準常態分佈。
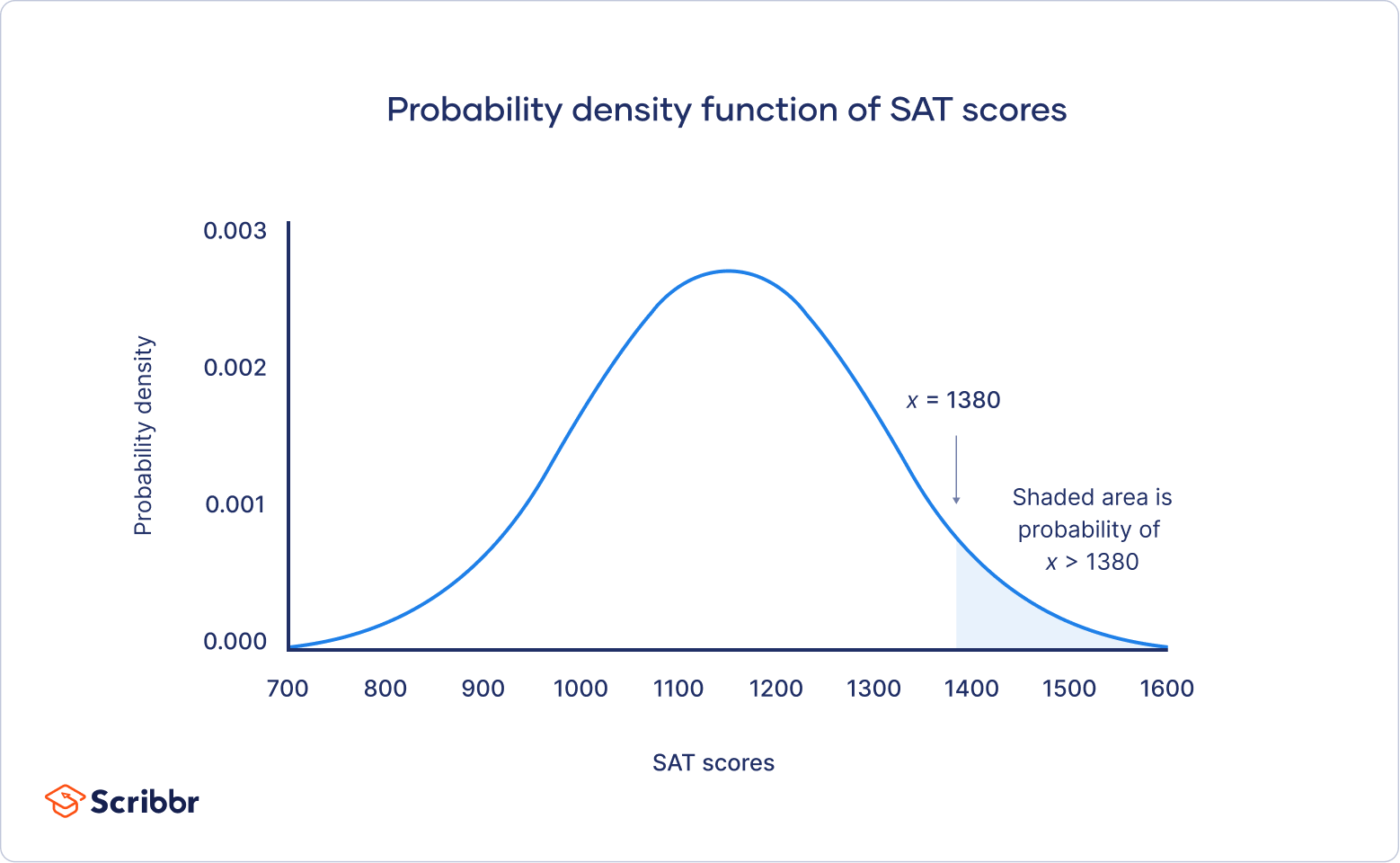

標準常態分佈與資料覆蓋率
- 約68.27%的數據在[μ−σ, μ+σ]範圍內;
- 約95.45%在[μ−2σ, μ+2σ];
- 約99.73%在[μ−3σ, μ+3σ]。
| 標準差範圍 | 覆蓋比例 |
|---|---|
| [μ−σ, μ+σ] | 約68.27% |
| [μ−2σ, μ+2σ] | 約95.45% |
| [μ−3σ, μ+3σ] | 約99.73% |
多元高斯分佈
當多個變數聯合服從高斯分佈時,採用多元高斯分佈:
$ f(\mathbf{x}) = \frac{1}{ (2\pi)^{k/2}|\Sigma|^{1/2}} \exp\left(-\frac{1}{2}(\mathbf{x}-\mu)^T \Sigma^{-1} (\mathbf-1} (
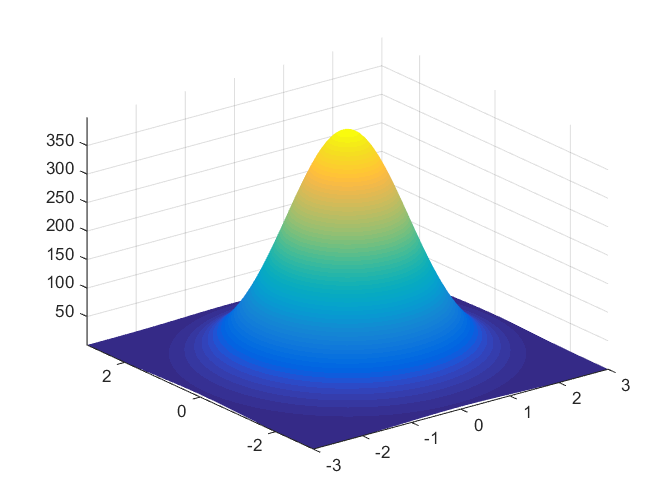
- Σ為協方差矩陣,k為維數
高斯分佈的應用場景大盤點
中心極限定理解釋了高斯分佈為何“無處不在”,只要獨立同分佈變量樣本足夠大,其和或均值趨於高斯分佈。
| 應用場景 | 關鍵作用 | 產業代表 |
|---|---|---|
| 測量誤差分析 | 描述觀測誤差分佈 | 物理學、天文 |
| 品質管制 | 預測產品偏差分佈 | 工業產線 |
| 考試成績排序 | 考生成績分佈 | 教育 |
| 機器學習模型 | 參數初始化 | 人工智慧 |
| 風險管理 | 金融資產波動 | 金融 |
| 影像處理 | 高斯模糊/濾波 | 數位影像 |
| 新藥實驗統計 | 反應、副作用分佈 | 醫藥 |
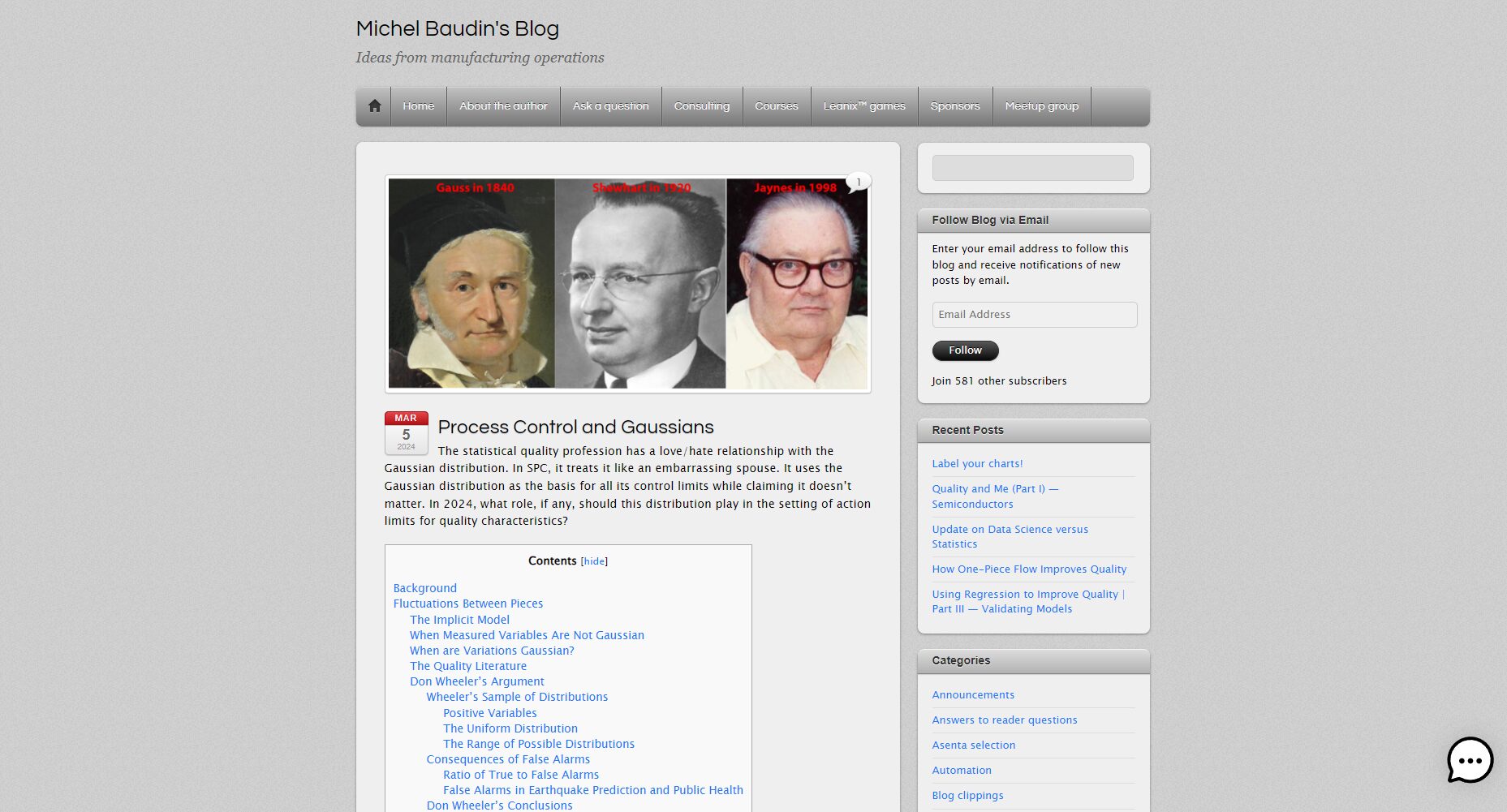
品質檢測:工業標準與自動化
高斯分佈用於評估產品指標(如尺寸、重量)是否在可接受範圍。例如螺絲長度μ=10mm,σ=0.05mm,可設定標準警戒線。
教育評分:曲線評定法
大型考試(如高考)常假定成績呈高斯分佈,透過統計參數計算各分段賦值,以減少極端分數帶來的評價誤導。
人工智慧與深度學習
- 神經網路權重初始化(如PyTorch、TensorFlow的normal隨機函數)
- GAN/VAE中雜訊樣本生成
- 機器學習演算法中的參數最大似然估計
資料預處理與異常檢測
在金融、網路安全等產業,若資料服從高斯分佈,則超出[μ±3σ]的點極有可能是異常,需重點關注或剔除。
高斯分佈的常見誤區揭秘
| 常見迷思 | 真相解讀 |
|---|---|
| 所有自然現像都是高斯分佈 | 極端如金融危機等經常偏離高斯,呈現「胖尾」現象 |
| 標準差即極限取值範圍 | 雖3σ覆蓋達99.7%,但極端值依然可能出現 |
| 均值即眾數 | 偏態分佈時平均值與眾數可能不一致 |
| 標準差能刻畫全部特徵 | 多峰、厚尾或偏態時需更高階統計量,如偏度、峰度 |
AI工具推薦:自動檢定資料常態性,可使用Statistical Tests AI批量做Shapiro-Wilk或Anderson-Darling測試。
產業專家觀點:高斯分佈的時代價值
知名人工智慧專家何教授表示:「“高斯分佈早已嵌入科學計量、金融、智慧診斷、影像辨識等每一環節。隨著資料量增加與演算法最佳化,正確選用分佈假設與防範異常尤為重要。”」忌盲目依賴高斯假設,建議結合偏度厚尾等敏感檢定。
高斯分佈相關算式與AI平台整理
| 場景 | 建議算式/工具 | 官方平台 |
|---|---|---|
| 偵測常態性 | Shapiro-Wilk, KS檢驗 | scikit-learn |
| 參數估計 | 最大似然估計MLE | SciPy |
| 數據標準化 | z-score歸一化 | sklearn.preprocessing |
| 異常檢測 | 3σ規則標記outlier | AnomalyDetection AI |
媒體案例追蹤:現實中的高斯分佈
案例1:金融風險管理失誤
某國際銀行僅用高斯分佈估算虧損風險,忽略“胖尾”,在2008年次貸危機造成巨量損失,成為常態假設的反思案例。
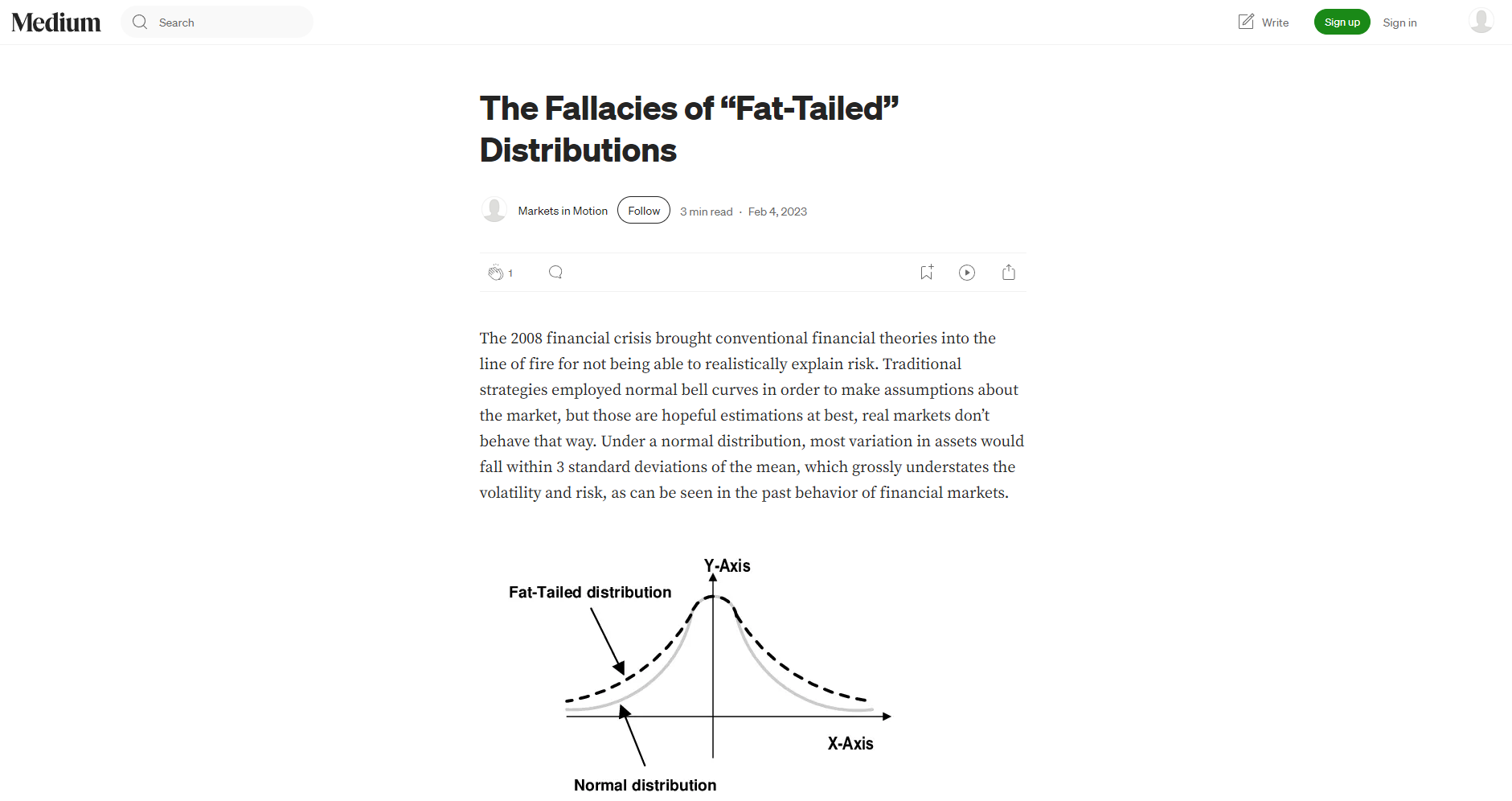
案例2:工業自動化生產
豐田汽車每道工序以高斯分佈設定警示邊界,精準管控品質並提前發現設備故障。
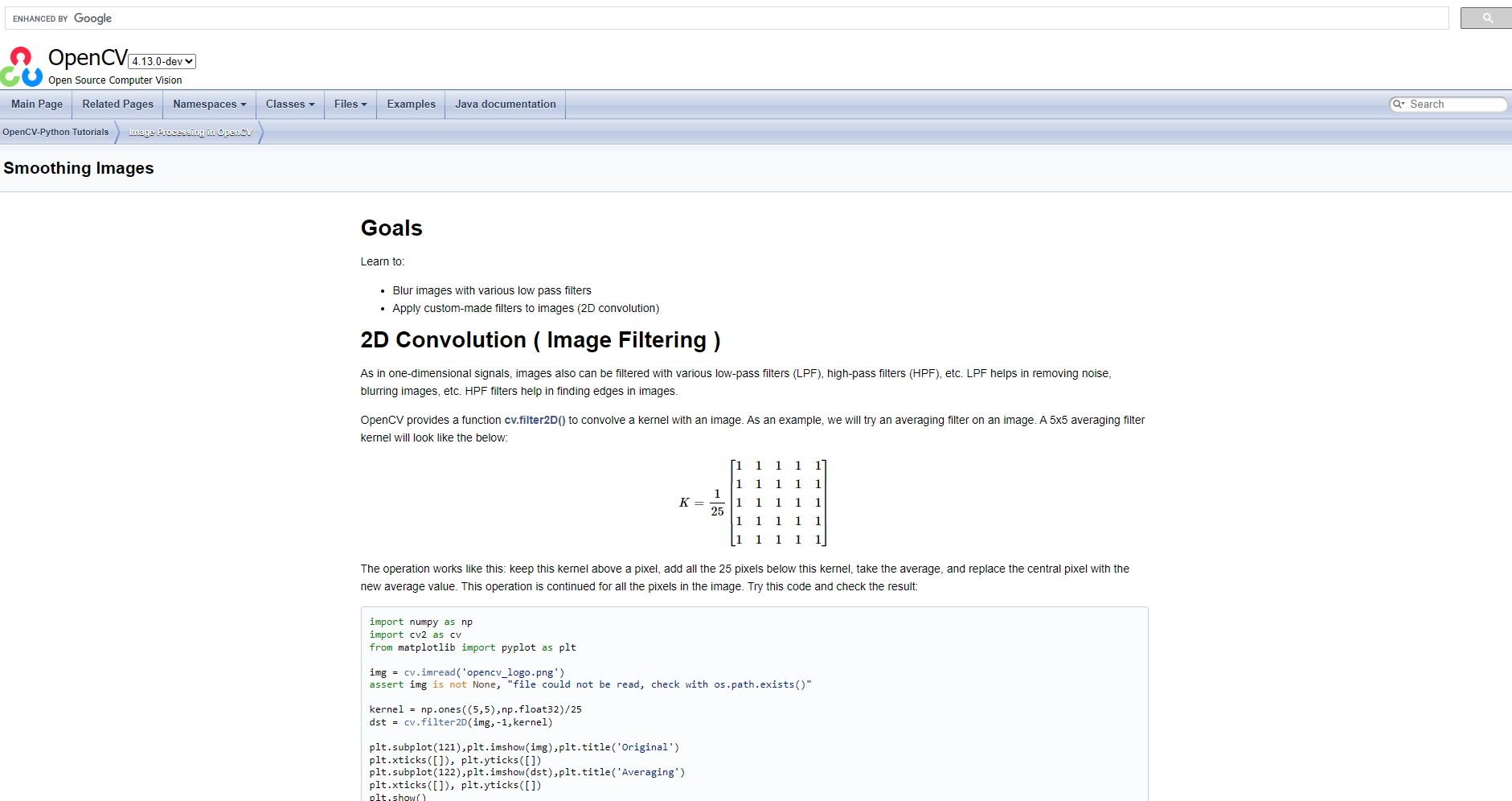
案例3:AI影像處理
高斯模糊是降噪常用演算法,如OpenCV的cv2.GaussianBlur在去除影像高頻雜訊、提升邊緣偵測穩定性方面效果突出。
小知識快問快答
| 問題 | 答案 |
|---|---|
| 如何判定資料是否為高斯分佈? | 可畫直方圖、機率紙、QQ圖;輔以常態檢驗 |
| 小樣本適合高斯分佈嗎? | 樣本數太小結果不可靠,建議n>30以上 |
| 多特徵資料能用一維高斯分佈嗎? | 建議多元高斯描述特徵間聯繫 |
| 標準差很大有何風險? | 波動大、異常多,需加強異常點監控 |
在數位智慧時代,高斯分佈的核心價值已遠超過統計學,貫穿人工智慧、工業、風控等關鍵領域。科學理解其本質與邊界是每位資料實務工作者的必修課!
© 版權聲明
文章版權歸作者所有,未經允許請勿轉載。
相關文章



暫無評論...