

AI Photos
AI Photos是一款支持文本描述、照片快速生成高质量图片、插画和短视频的AI图片生成工具,适用多平台和多场景。
Collaborative LLM Tool(Petals)为AI大模型带来革命性的低门槛分布式推理与微调解决方案。用户仅需消费级GPU便可通过P2P网络,协作参与Llama、Mixtral等主流开源大模型的实时推理和微调。无需高昂服务器成本,极低准入门槛,支持丰富开发接口,适合AI开发者、科研者及创新企业试验AIGC应用。Petals完全开源免费,推动了AI算力公益和模型开放创新,但对于商用保障、激励与安全尚在完善中。
Collaborative LLM Tool(Petals):重塑AI大模型的民主化合作新格局
在大语言模型(LLM)主导AI革命的时代,高效、低门槛的分布式模型推理与微调成为AI研究与应用的强烈诉求。Collaborative LLM Tool(Petals)通过协作式LLM的创新机制,让全球开发者用普通GPU即可参与超大规模大模型的推理和训练,为AI产业带来全新范式。本文将从功能、价格、使用方式、适用人群、优势与局限、FAQ等多维度,全面解析这个AI基础设施的重要创新。

Petals由BigScience、Yandex Research等团队推动,是一种BitTorrent式分布式大模型推理与微调平台。用户可用普通GPU通过P2P协作网络参与Llama 3.1、Mixtral、Falcon、BLOOM等超大模型的推理与微调,极大降低AI大模型的使用门槛,把AI能力带入大众。其核心理念为:每台电脑都是虚拟超级算力网络的一员。
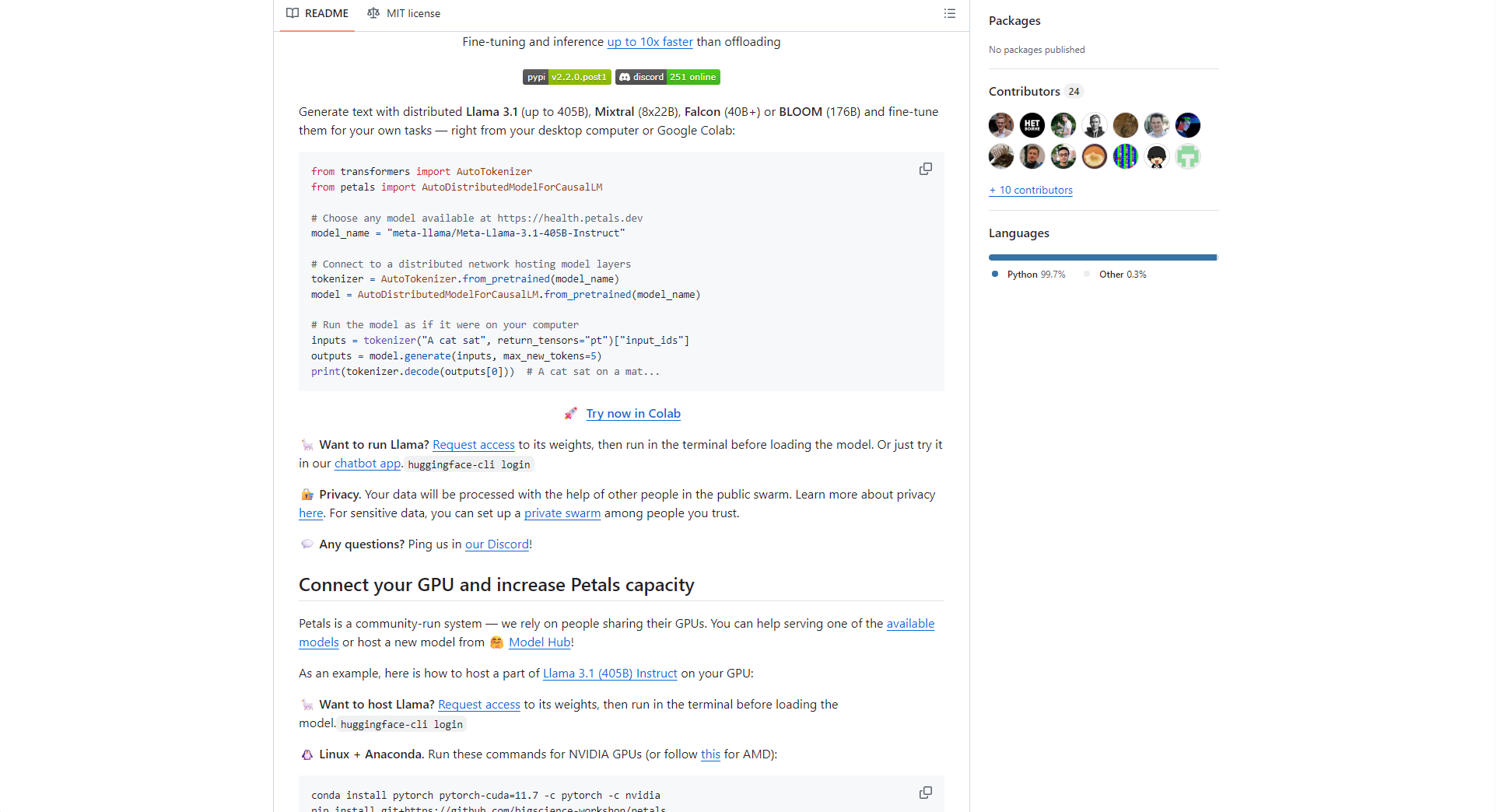
| 功能类别 | 主要亮点 | 支持方式 |
|---|---|---|
| 推理协作 | 多人分摊大模型负载 | 分布式P2P网络 |
| 开源模型支持 | Llama/Mixtral/BLOOM/Falcon等 | Transformers |
| 微调定制 | 自定义、增量微调 | API及PyTorch |
| 节点贡献 | GPU算力共享 | 专用python包 |


| 用户角色 | 费用 | 备注 |
|---|---|---|
| 普通用户 | 免费 | 社区P2P主网 |
| 贡献者 | 免费(能源自付) | 算力贡献提升容量 |
| 企业/商业部署 | 议价/社区支持 | 尚无明确付费方案 |
from transformers import AutoTokenizer, pipeline
from petals import AutoDistributedModelForCausalLM
model = AutoDistributedModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-70B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-70B-Instruct")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
pipe("你好,介绍Petals平台的优势:", max_new_tokens=50)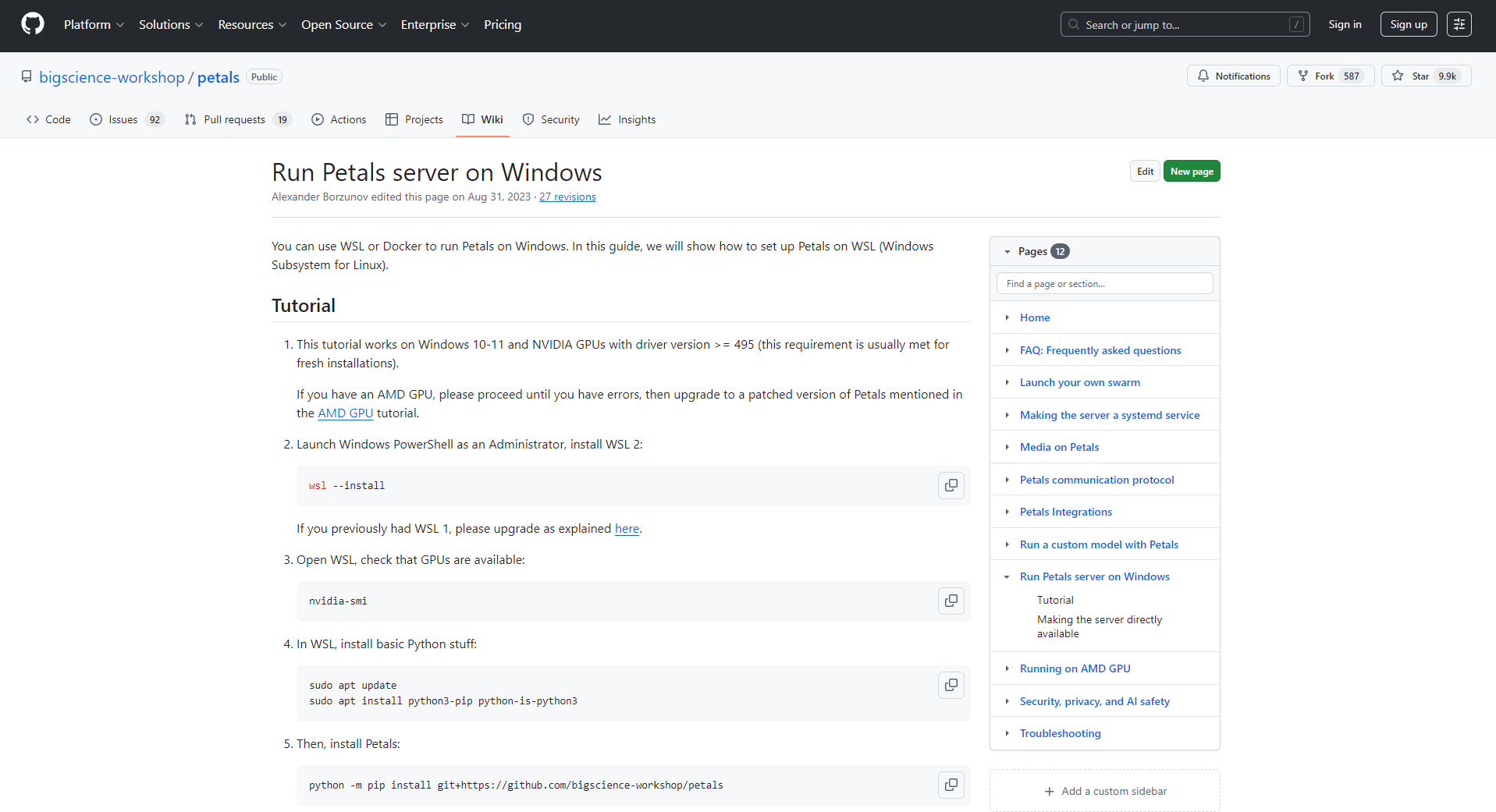
| 应用方向 | 场景实例 | 使用方式 |
|---|---|---|
| NLP应用 | 自动问答、聊天机器人 | 推理与定制微调 |
| 教育/科研 | 模型原理教学与实验 | 查看中间层/自定义采样 |
| 内容生成 | 文章、代码生成 | API开发 |
| 科技公益 | 算力捐赠社区 | 节点贡献 |
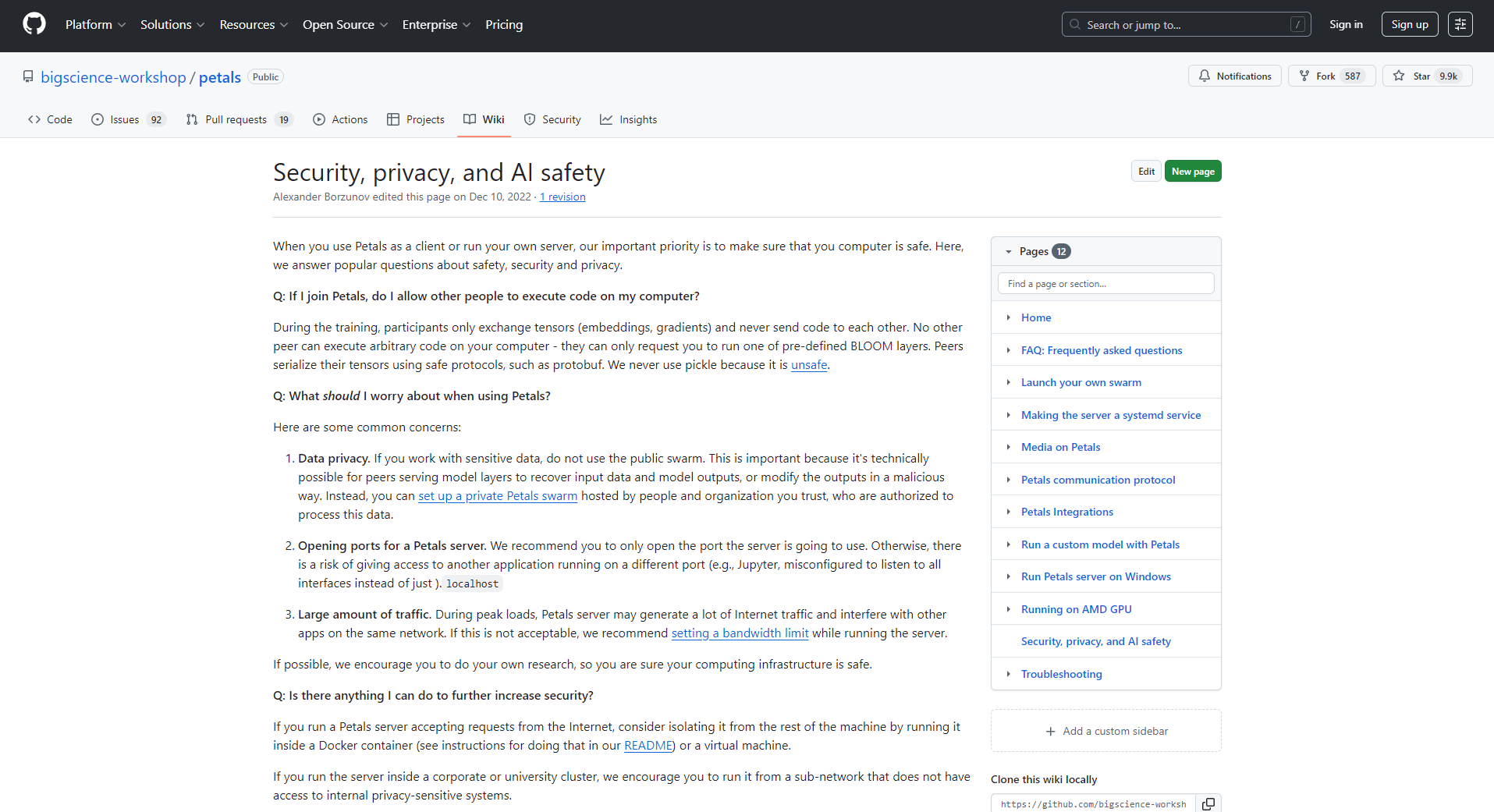
Petals基于BitTorrent分层P2P模型分布,每节点仅托管部分模型层,数据流经节点进行推理与训练,低配硬件亦可协同大模型AI,极大推动了AI办公工具的全民化普及。
| 技术方式 | 中心化服务器 | Petals分布式 |
|---|---|---|
| 硬件要求 | 极高 | 普通GPU/Colab |
| 单点故障 | 易受限 | 弹性切换 |
| 性能拓展 | 有限 | 节点越多越强 |
| 成本 | 高额 | 零门槛/共享 |
在AI大模型门槛攀升之际,Collaborative LLM Tool(Petals)通过分布式创新设计与开源协作理念,为AI产业带来“人人可参、人人可用”的新模式。它极大推动了AI办公工具(如自动写作、办公自动化、推理与内容生成)的普及和民主化。更多详情请参考Petals官网和GitHub主页。
本站AI 喵导航提供的Collaborative LLM Tool都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI 喵导航实际控制,在2026年1月17日 下午6:22收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI 喵导航不承担任何责任。
