

DeepL Translation
DeepL Translate is a multilingual online translation tool that uses advanced AI neural network technology and is known for its natural and fluent translation.
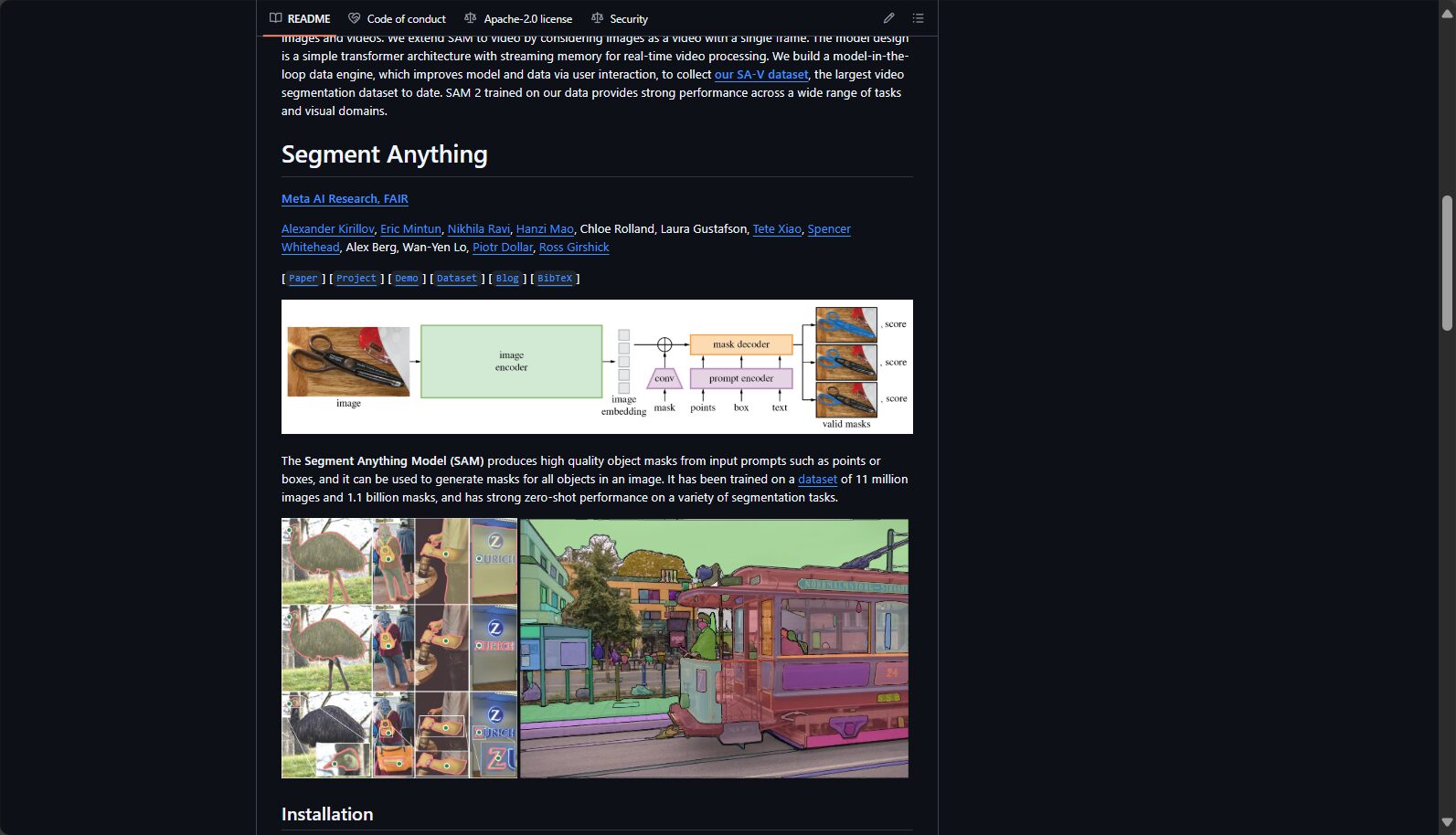
Segment Anything Model (SAM) is a general-purpose image segmentation model developed by Meta AI. It supports real-time interactive segmentation in any scenario and has powerful zero-shot generalization capabilities.
Segment Anything Model (SAM)是由Meta AI(前Facebook AI Research)团队开发的通用型图像分割基础模型。其最引人瞩目的特点在于:支持任何物体、任何场景、任何提示下的实时交互式分割,并凭借其超大规模训练数据集SA-1B数据(超过11万张图像、10亿分割掩码)在业内树立了新标杆。
该项目不仅开放了权威模型权重、详细的SDK和Demo网站,还发布了视觉分割有史以来最大的数据集,对应用和学界都带来了巨大推动。
SAM能够接受不同类型的提示(如点选、框选、粗略掩码等)来实现灵活的分割,这一方式极大提升了用户交互体验与模型适应能力。
常见提示类型如下:
SAM采用大规模、多类型的数据训练,具备出色的零样本能力,可以在从未见过的图像或物体类别上自动实现准确分割,无需专门“微调”或继续训练。
SAM提供不同规模的模型(如ViT-B、ViT-L、ViT-H),以适配不同的算力环境和分割精度需求,支持理想的弹性部署。
常见模型性能对比表(来自官方GitHub):
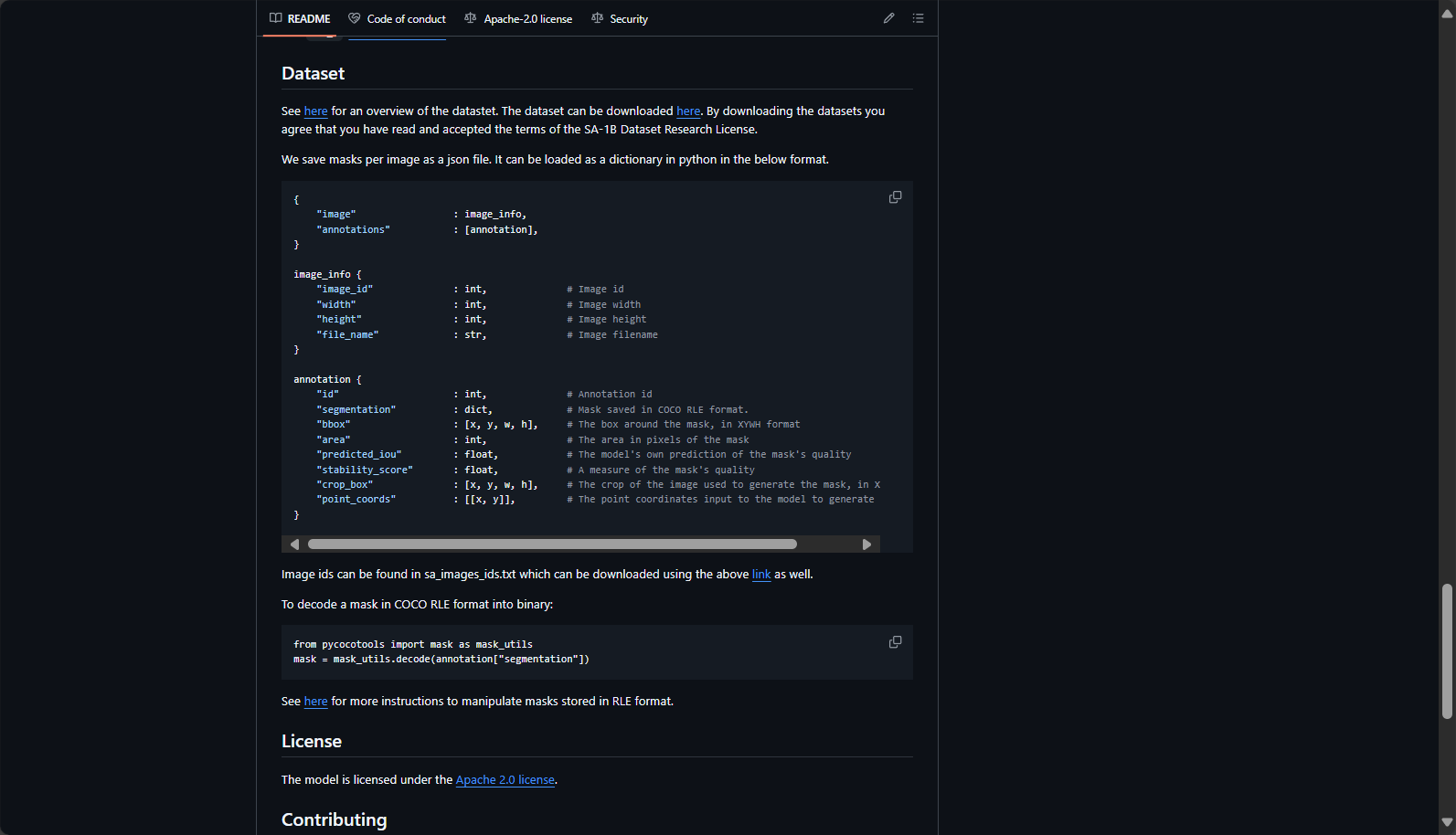
| Model | 尺寸 | Applicable Scenarios | 推理速度 | 权重下载 |
|---|---|---|---|---|
| ViT-H (Huge) | 最大 | 最佳精度,需高算力 | Slower | 权重下载 |
| ViT-L (Large) | 较大 | 精度与速度均衡 | medium | 权重下载 |
| ViT-B (Base) | Base | 适合快速应用、轻算力场景 | 快 | 权重下载 |

通过Transformer架构与多尺度视觉特征融合,SAM能够自动生成精细的分割掩码,边界清晰可用,显著减少后期人工修正负担。
除了常规SDK,SAM官方还提供了网页版Demo和RESTful API,方便不同背景的用户快速试用和集成。
更多内容与演示,请访问 SAM官方Demo页面。
目前,SAM项目本身完全开源且免费。Meta团队开源了模型权重、训练代码和示例,世界各地开发者和学者均可免费下载和研究(开源协议详情)。
表:SAM官方价格与方案
| Solution/Version | Fee details | Main content | illustrate |
|---|---|---|---|
| 基础SAM模型 | free | 训练权重、源码、Demo、数据集 | 需自有算力环境部署 |
| Web DEMO | free | 在线页面或API | 不保证大规模高并发 |
| 商业扩展 | Pending | 第三方云推理、企业支持 | Meta暂无直接商用SaaS产品 |
Remark: 如需求大规模线上API推理,推荐考虑第三方云AI公司(如AWS、Azure、Huggingface)上部署,费用视具体厂商与配置,详情可参考Huggingface Hub SAM部署。
SAM官方文档和社区教程为开发者提供了多样的本地部署与API接口选择。基本流程如下:
A. 安装与环境准备
git clone https://github.com/facebookresearch/segment-anything.git按需下载ViT-B/L/H权重文件。
pip install -e segment-anything
B. Python调用样例
from segment_anything import SamPredictor, sam_model_registry
checkpoint = "./sam_vit_b_01ec64.pth"
sam = sam_model_registry["vit_b"](checkpoint=checkpoint) # 选择模型类型
predictor = SamPredictor(sam)
# 加载图片
import cv2
image = cv2.imread('path/to/image.jpg')
predictor.set_image(image)
# 以点/框提示进行分割
input_point = [[100, 150]] # [(x, y)]
input_label = [1] # 1为前景点
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True
)C. Web DEMO在线分割
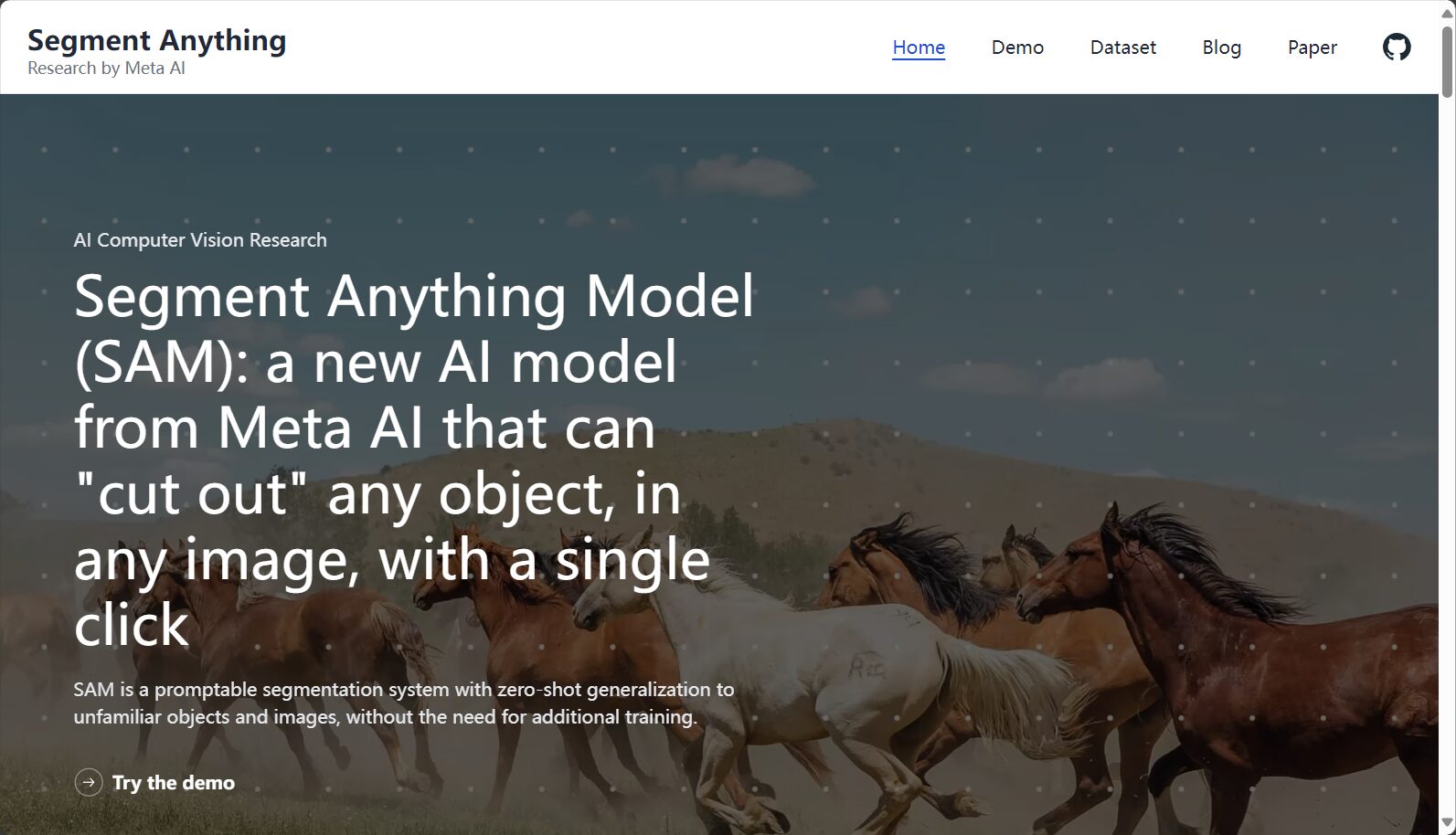
D. 集成Label Studio数据标注
SAM已被集成到主流的开源标注平台Label Studio之中,大幅提升数据标注效率。具体步骤可参见官方集成教程。
SAM的独创设计,使其适配范围非常广泛:
适用行业场景举例表
| Application areas | Specific scenarios | SAM的优势 |
|---|---|---|
| Healthcare | 病理切片、X光/CT分割 | 可自动分割异常、界面清晰 |
| autonomous driving | 城市街景/路面物体识别 | 鲁棒泛化,多条件支持 |
| AR/VR | 增强现实物体实时“抠图” | 秒级响应,体验流畅 |
| Content creation | 图像编辑、换背景、艺术加工 | 边界处理极其自然 |
| Data labeling | 海量半自动掩码标注 | 极大降低人工成本 |
SAM之所以能实现“Segment Anything(任意分割)”,主要得益于以下三大创新模块:
多年来,分割领域主流依然是U-Net、Mask R-CNN、DeepLab等,但它们普遍存在泛化能力弱、成本高、交互式支持差等问题。
对比表:SAM与主流分割AI训练模型
| Dimension | SAM (Segment Anything) | 传统模型(如Mask R-CNN等) |
|---|---|---|
| 分割方式 | 支持“提示”分割/零样本 | 需专门训练/微调 |
| 泛化能力 | 高,支持未知类别 | 低,需定向标定 |
| 运行效率 | 快速,支持实时/交互 | 高精度模式速度较慢 |
| 开源便捷 | 全开源、界面&API丰富 | 多需自定义开发 |
欲查看更多实际对比与业界反馈,请关注 Huggingface Segment Anything 页面 的开源测试讨论。
答:可以。SAM输出的掩码高质量、边界清晰,非常适合作为下游语义分割、实例分割、目标检测等任务的数据标注来源。已有众多数据标注平台(如Label Studio)将SAM集成为半自动掩码标注工具,有效提升了训练数据制作效率。
answer:SAM的资源消耗与模型类型有关:
详细部署建议见官方GitHub说明
答:目前SAM原生版本主要支持点、框、掩码作为Prompt,正在研发文本提示功能。不过,业界已有团队将CLIP等文本-视觉模型与SAM结合,实现了“文本自动分割”能力,相关成果在Semantic Segment Anything (SSA)和CLIP-SAM等项目中有演示。
This site's AI-powered navigation is provided by Miao.Segment Anything Model (SAM)All external links originate from the internet, and their accuracy and completeness are not guaranteed. Furthermore, AI Miao Navigation does not have actual control over the content of these external links. As of 12:17 PM on August 6, 2025, the content on this webpage was compliant and legal. If any content on the webpage becomes illegal in the future, you can directly contact the website administrator for deletion. AI Miao Navigation assumes no responsibility.
