crawl4ai Complete Guide: How to efficiently crawl AI website content and improve data collection efficiency?
crawl4aiA product aimed atNew web crawler tools for AI data acquisition scenarios,haveNo-code operation, intelligent anti-scraping, anti-blocking and extensible templatesIt boasts numerous advantages. This article provides an authoritative and comprehensive analysis of its core functions, practical operation guidelines, advanced efficiency improvement techniques, and compliance matters, helping enterprises and developers efficiently and easily collect AI website content, greatly improving the quality and efficiency of data crawling.
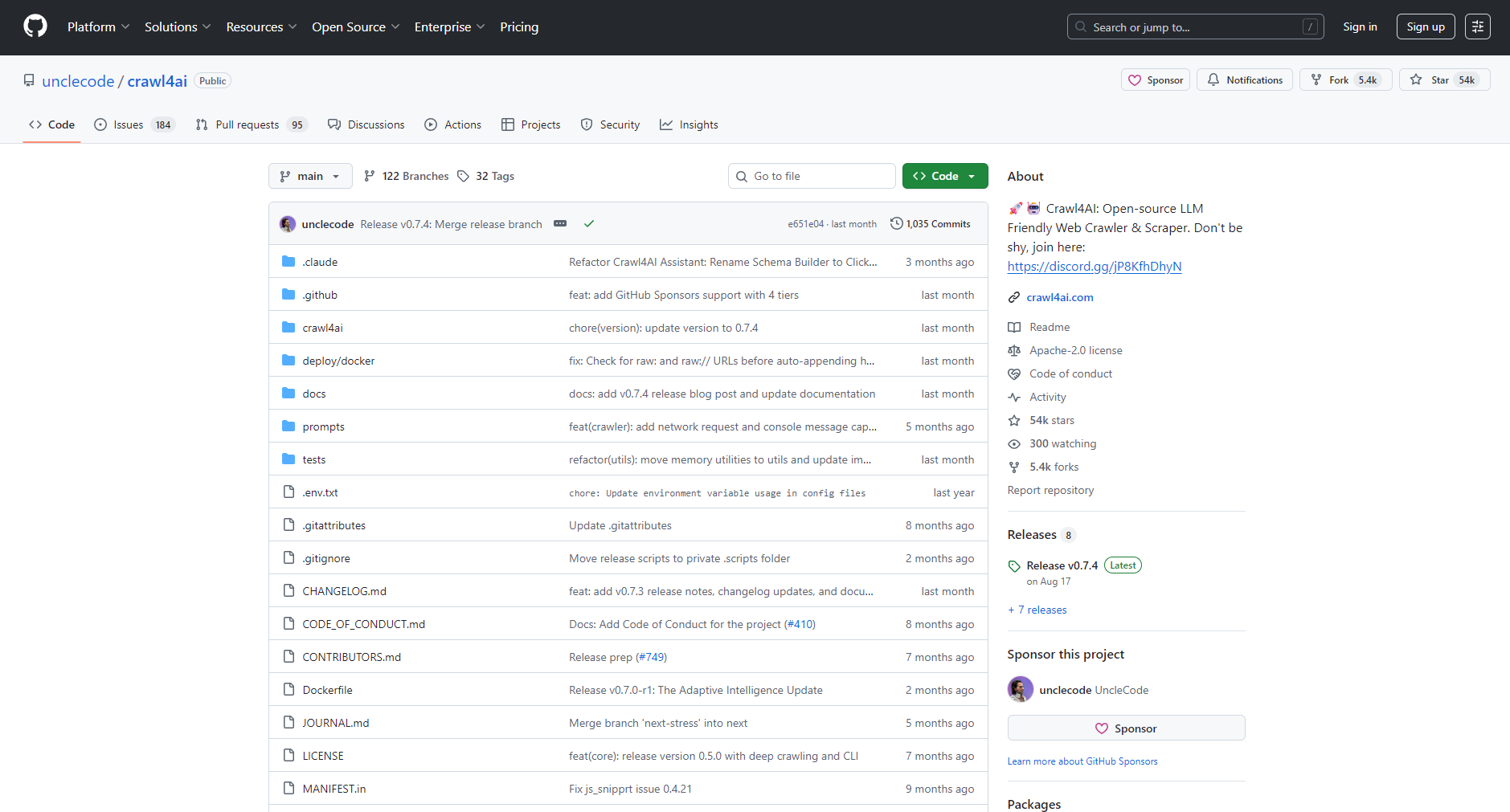
Introduction and core advantages of crawl4ai tool
What is crawl4ai?
crawl4aiIt is an intelligent web scraping platform designed specifically for large-scale data collection in the AI era. It supports multi-site, no-code, high-concurrency scraping, and features an embedded intelligent anti-scraping mechanism and diverse scene templates. It is considered an important data scraping tool in the fields of artificial intelligence and data analysis.
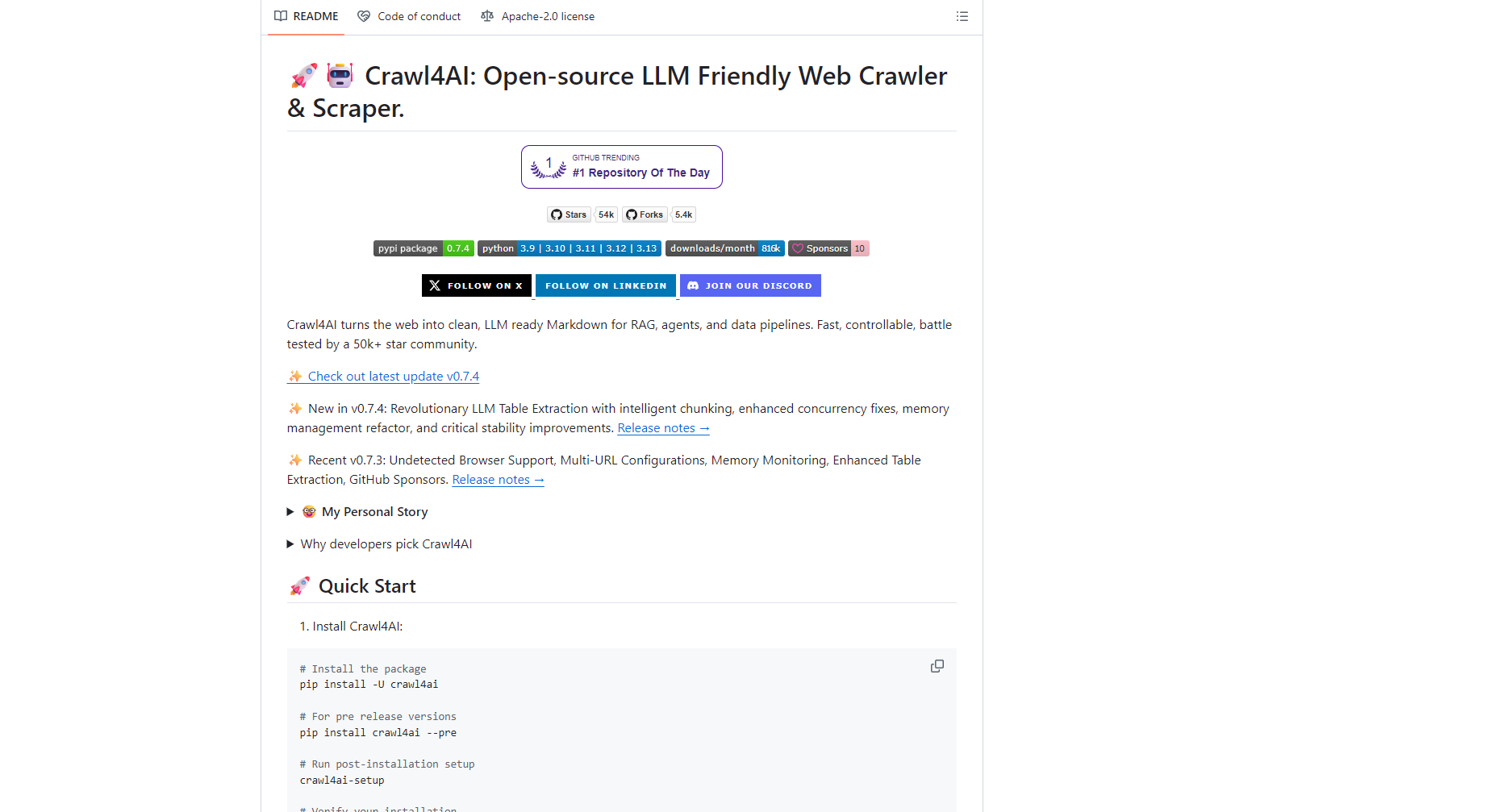

| Functional modules | Main function | User-oriented |
|---|---|---|
| Automated web page scraping | Batch crawling of target web pages and automatic content parsing | Developers/Product Managers |
| Intelligent anti-crawler | Automatically avoid website blocking and frequency limits | Data Scientist/Researcher |
| Multi-format data storage | Supports exporting in multiple formats such as CSV, JSON, and MySQL. | Enterprise Data Team |
| Scenario-based template library | Built-in AI website and news site data collection templates | No-code users, beginners |
crawl4ai Product Highlights
- Cloud-based distributed architecture, high concurrency and fault-tolerant parallel crawling
- The anti-scraping mechanism is robust and can automatically handle IP blocking and CAPTCHA issues.
- Both visualization and API modes are available, adaptable to development and no-code scenarios.
- Rich scene templates, supporting AI-powered content collection from mainstream websites and custom crawling rules.
Multiple AI companies in the industry have reported that crawl4ai can improve the efficiency of data crawling of over 901 TP3T, making it an important foundational tool for large model training and content acquisition.
crawl4ai: A Practical Guide to Efficiently Crawling AI Website Content
Five steps to quickly get started with crawl4ai
- Registration, login, and API applicationGo to the crawl4ai official website to register and obtain an API key.
- Target website and content settingsSelect the AI-related websites, content scope, and depth of data collection you wish to crawl.
- Template selection & custom rules: Use the built-in template or set it through custom fields on the page.
- Smart protection settingsEnable proxy and anti-scraping strategies to prevent being blocked.
- Export and API IntegrationOne-click export of data in multiple formats or API integration with AI training data pipelines.
Comparison of crawl4ai with traditional web crawling tools
| Comparison items | crawl4ai | Traditional general web crawler |
|---|---|---|
| Deployment method | SaaS/Cloud | Local/Self-built |
| Anti-crawling capability | Intelligent, advanced | Weak, requires manual maintenance |
| Operation method | No-code/Visual/API | Scripts need to be written |
| Concurrency performance | Distributed high concurrency | limited |
| Scene template library | Rich and diverse | 无 |
| Adapt to AI training scenarios | Highly adaptable | Additional processing required |
Applicable scenarios for crawl4ai to collect data from AI websites
- Academic paper collectionAutomatically extracts metadata from hundreds of thousands of papers on Arxiv, Google Scholar, and other sources.
- AI Information and News AggregatorReal-time aggregation of popular AI news from platforms such as Zhihu and Medium
- Social and Q&A content scrapingCollect high-quality technical Q&A from Reddit, Zhihu, etc., for training AI dialogue models.
- Data and code scrapingCollect datasets and code repositories from platforms such as Kaggle and GitHub.
Advanced Techniques for Improving Craw4ai Data Acquisition Efficiency
- Intelligent deduplication and data quality improvementCustom deduplication algorithm to improve sample uniqueness and high-quality data.
- Enhance the data labeling systemBuilt-in NLP tags and automatic classification accelerate the data preprocessing process.
- Resuming data collection after interruption and anomaly alarmAutomatic resume recording from breakpoints, error retries, and timely alarms and strategy switching when encountering IP/format changes.
- One-click access to mainstream AI platforms/data lakesIt can quickly connect to platforms such as AWS S3, BigQuery, and Databricks via API or standard format.
crawl4ai performance comparison with market tools
| Tools/Platforms | Anti-crawling capability | Template support | Performance scalability | user interface | AI adaptability |
|---|---|---|---|---|---|
| crawl4ai | Extremely strong | Rich | Cloud-based distributed | Visualization + API | Extremely strong |
| Octoparse | generally | generally | limited | Visualization | generally |
| Scrapy | Manual operation required | 无 | Manual maintenance required | pure code | High threshold |
| Scrape API | 强 | generally | Professional services | API-based | 好 |
crawl4ai Operations and Data Security Compliance Guidelines
Legal compliance and privacy protection
crawl4ai strictly adheres to the robots.txt protocol and local laws, provides automatic compliance alerts, and supports enterprises in customizing the filtering of sensitive information to ensure the legality and security of data.
crawl4ai Open Ecosystem and Developer Support
The platform offers comprehensive APIs, SDKs, and documentation, supports mainstream programming languages, and is easy to integrate into various enterprise-level data pipelines and AI frameworks.
Conclusion
In the AI era, the efficiency and intelligence of data collection directly impact a company's competitiveness. crawl4ai, with its powerful anti-crawling capabilities, low-barrier operation, and top-tier distributed performance, has become an industry leader in AI data crawling.Whether you have AI research or business data needs, you can efficiently and compliantly obtain high-quality AI website content through crawl4ai, helping businesses and individuals drive intelligent data.
For more details, please visitcrawl4ai official websiteGet more information.
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.
Related posts


No comments...