
What is overfitting? 5 effective ways to avoid overfitting that machine learning beginners should know by 2025.
Overfitting is a term that will be used in 2025.Machine learning and artificial intelligenceModel error traps that beginners should pay the most attention to.This article systematically interprets the phenomenon, causes, and detection methods of overfitting, and...Analyzing 5 powerful industry methods to avoid overfitting (early stopping, data augmentation, regularization, feature selection, and ensemble learning)With the latest AI cloud platforms and practical tool recommendations, this course helps beginners effectively improve their model generalization ability and lay a solid foundation for AI practice.

What is overfitting? The biggest challenge for beginners in the development of machine learning.
Definition and phenomena of overfitting
Overfitting refers to a machine learning model becoming so "good" at learning from the training data that it is unable to effectively predict unknown data.The model not only learns the real patterns in the data, but also treats the noise in the training data as a pattern that must be memorized.
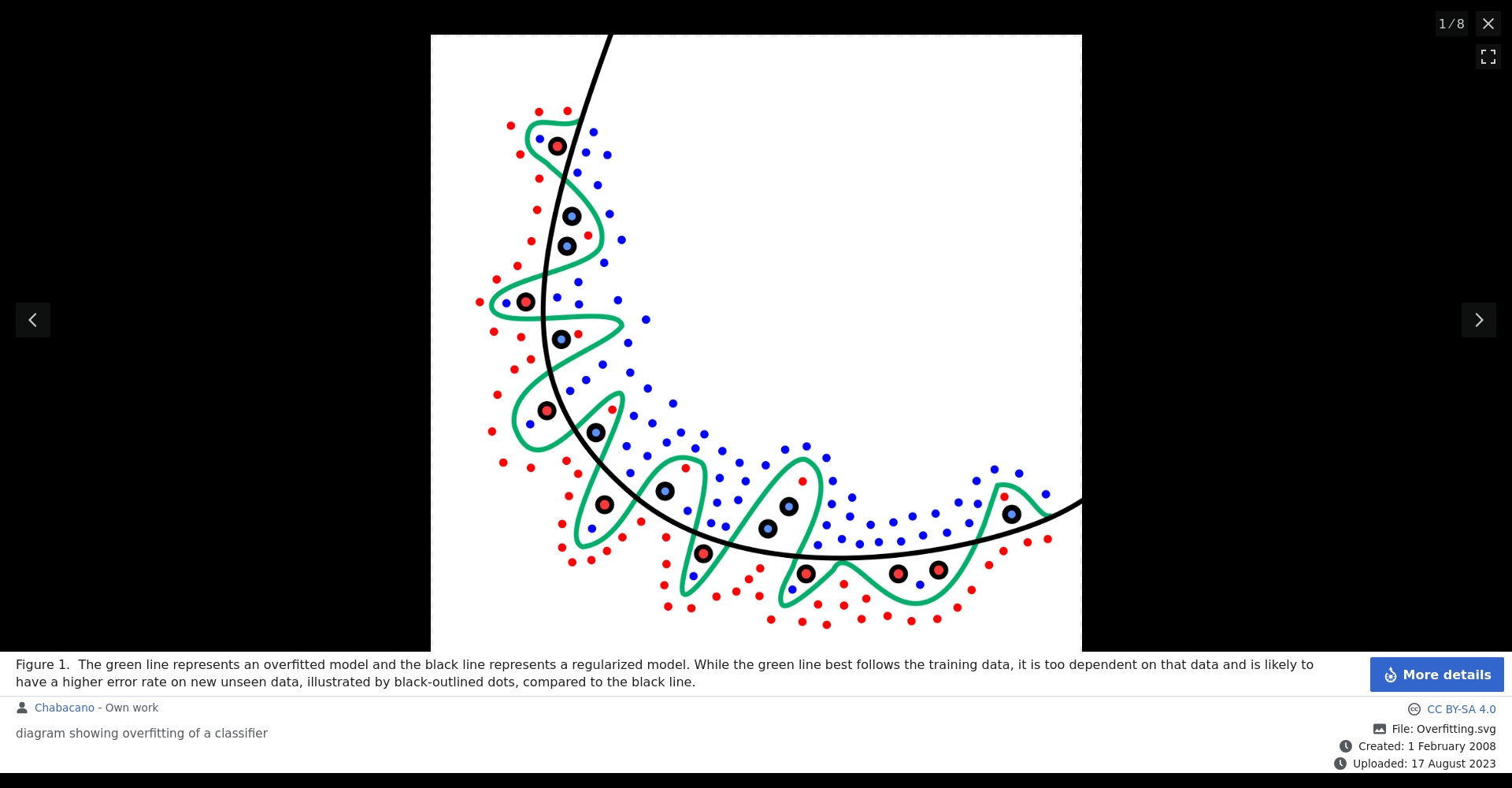
Overfitting can cause a model to perform exceptionally well on the training set, but its accuracy will plummet when faced with new data, rendering it ineffective for reasoning and prediction.By 2025, with the widespread application of deep learning in fields such as image recognition and NLP, the overfitting problem will become increasingly important.
Common causes of overfitting
- The training dataset is too small or there are insufficient samples.
- The data contains a lot of meaningless noise.
- Model training time is too long
- The model structure is too complex.
Overfitting is a typical error of the "high variance, low bias" type.In contrast, there is "underfitting".
How to determine if a model is overfitting?
Inconsistent performance between training and test sets
If a model achieves an accuracy of nearly 100% on the training set but significantly deteriorates on the test set, it is an overfitting warning sign.Typically, a portion of the data needs to be set aside for validation or a test set to evaluate the model's generalization.
k-fold cross-validation
k-fold cross-validation is the most commonly used method for detecting overfitting.The dataset is divided into K equal parts, and each part is used for testing and training in turn. The average performance is then used to test the robustness of the model. Modern cloud platforms such as Amazon SageMaker can automatically separate and issue warnings.
Five essential methods for machine learning beginners to avoid overfitting by 2025
The following is an overview of the current mainstream and effective overfitting prevention methods in the industry:
| Prevention methods | Main function | Applicable Scenarios | Common tools/platforms |
|---|---|---|---|
| Early Stopping | Prevent overtraining and reduce overfitting | Neural Network Deep Learning Training Process | TensorFlow, Keras |
| Data Augmentation | Increase training data diversity | Image recognition, speech, NLP | Augmentor, NLPAug |
| Regularization | Reduce model complexity and prevent excessive weights. | Linear/Nonlinear AI Models | Scikit-learn, PyTorch |
| Feature Selection | Remove useless input and reduce redundancy | Classification and prediction models | Feature-engine, XGBoost |
| Ensembling | Multi-model combination anti-interference | High variance decision trees, classification and regression | LightGBM, CatBoost |

Early Stopping
Early stopping is a method that automatically monitors the performance on the validation set during training and terminates training early to avoid overfitting.Frameworks such as Keras and TensorFlow have this mechanism built in.
Many international AI competition winning models employ fine-grained early stopping control, which will become the mainstream approach by 2025.
Data Augmentation
By fine-tuning and altering the original data (such as image rotation or text replacement), artificially increasing sample diversity effectively prevents the model from memorizing specific data details.
Standardized tools such as Albumentations and NLPAug can automatically generate amplified samples in batches.
Regularization
Adding a "penalty term" to the loss function to limit excessive parameter expansion and suppress model complexity is an essential technique in AI engineering and competitions.Mainstream includes:
- L1 regularization (improves feature sparsity)
- L2 regularization (limiting weight magnitude)
- Dropout (random deactivation of neural network units)
Feature Selection
It automatically filters valid input variables and eliminates redundant impurities, greatly improving the simplicity and generalization ability of the model.Boosting algorithms such as XGBoost and LightGBM have this feature built-in.
Ensembling
Integrating the judgments of multiple models improves overall stability and anti-interference capabilities, making it a powerful weapon against high variance overfitting.The mainstream methods include Bagging, Boosting, and Stacking.

Machine learning overfitting before and after case comparison
| Case/Steps | Before overfitting | After overfitting processing (using a strategy) |
|---|---|---|
| Image classification of cats and dogs (small sample size, no amplification) | Training set: 991 TP3T; Test set: 751 TP3T | The training set has 961 TP3T, and the test set has been increased to 891 TP3T. |
| User credit scoring (feature redundancy) | Overly detailed categories lead to inconsistent performance. | Feature optimization improves accuracy and provides stronger interpretability. |
| Speech recognition (overtraining) | Ignoring background noise results in high error. | Dropout + augmentation for more stable model performance |
The most recommended AI tools for overfitting detection and correction in 2025
| Tool/Platform Name | Feature Highlights | Link |
|---|---|---|
| Amazon SageMaker | Automatic training/validation of cuts, automatic warnings of overfitting | SageMaker |
| IBM watsonx.ai | Enterprise-level training and model parameter optimization | watsonx.ai |
| TensorFlow/Keras | Built-in modules for early stopping, regularization, and amplification. | TensorFlow |
| Scikit-learn | Enriched regular expressions, feature filtering, and cross-validation tools | Scikit-learn |
| LightGBM/XGBoost | Ensemble learning + feature selection + anti-overfitting | LightGBM、XGBoost |
Generative AI and machine learning have entered a period of explosive growth.The generalization ability of a model will determine whether AI can be applied in practice. A thorough understanding of the essence of overfitting, mastery of core prevention and detection technologies, and effective use of mainstream open-source and cloud tools are essential core competencies for every AI novice in 2025.
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.
Related posts


No comments...