
2025年,多模態大模型(VLM, Vision-Language Model)成為AI技術發展新高地。本文深度整理全球7大VLM核心產品,比較開源閉源、技術路線、應用場景與在地化能力,全面解析其最新優劣勢。文章適合開發者、企業決策者、科學研究工作者一站掌握AI視覺語言融合的最佳選用趨勢與部署建議。
VLM 2025年度多模態大模型工具總覽
在正式推薦前,先透過表格為讀者呈現2025年最受關注的7大VLM工具特性一覽:
| 名稱 | 開源/閉源 | 關鍵特色 | 文字上下文視窗 | API/自架 | 連結 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 閉源 | 通用多模態任務,極高彈性 | 10k~20k | 官方平台 | Google AI Studio |
| GPT-5 | 閉源 | 統一Transformer,多模態高效融通 | 128k | 官方平台 | OpenAI |
| Claude 4.1 Vision | 閉源 | OCR/圖表特化,強科學推理 | 200k | 官方平台 | Anthropic |
| Qwen 2.5-VL-72B | 開源 | 任意解析度/長視訊多模複雜任務 | 128k | API/自建 | Qwen-VL |
| Llama 4 Scout | 開源 | 混合專家機制,極高可擴展性 | 10k~100k | API/自建 | Llama 4 |
| MiniCPM-V 8B | 開源 | 超低參端側推理,全面影片/圖片理解 | 32k+ | API/自建 | MiniCPM-V |
| CogVLM 17B | 開源 | 微調SOTA效能,視覺+語言高分測試 | 16k | API/自建 | CogVLM |
表格說明:工具皆支援現代多模態融合主流需求,部分工具可透過Novita AI等平台低成本API存取。
全球視野:vlm多模態AI模型定義與應用價值
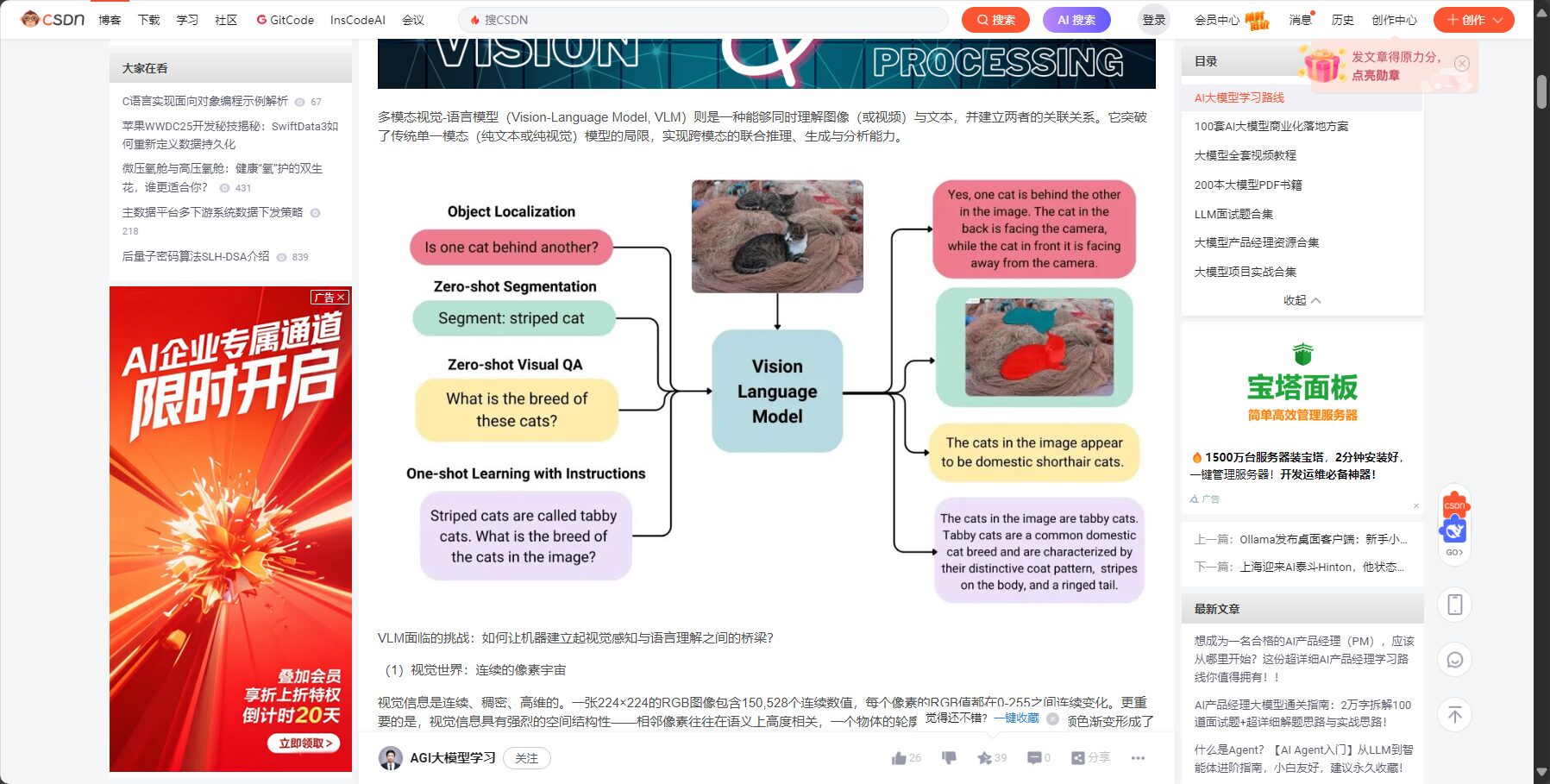
什麼是多模態大模型(VLM)?
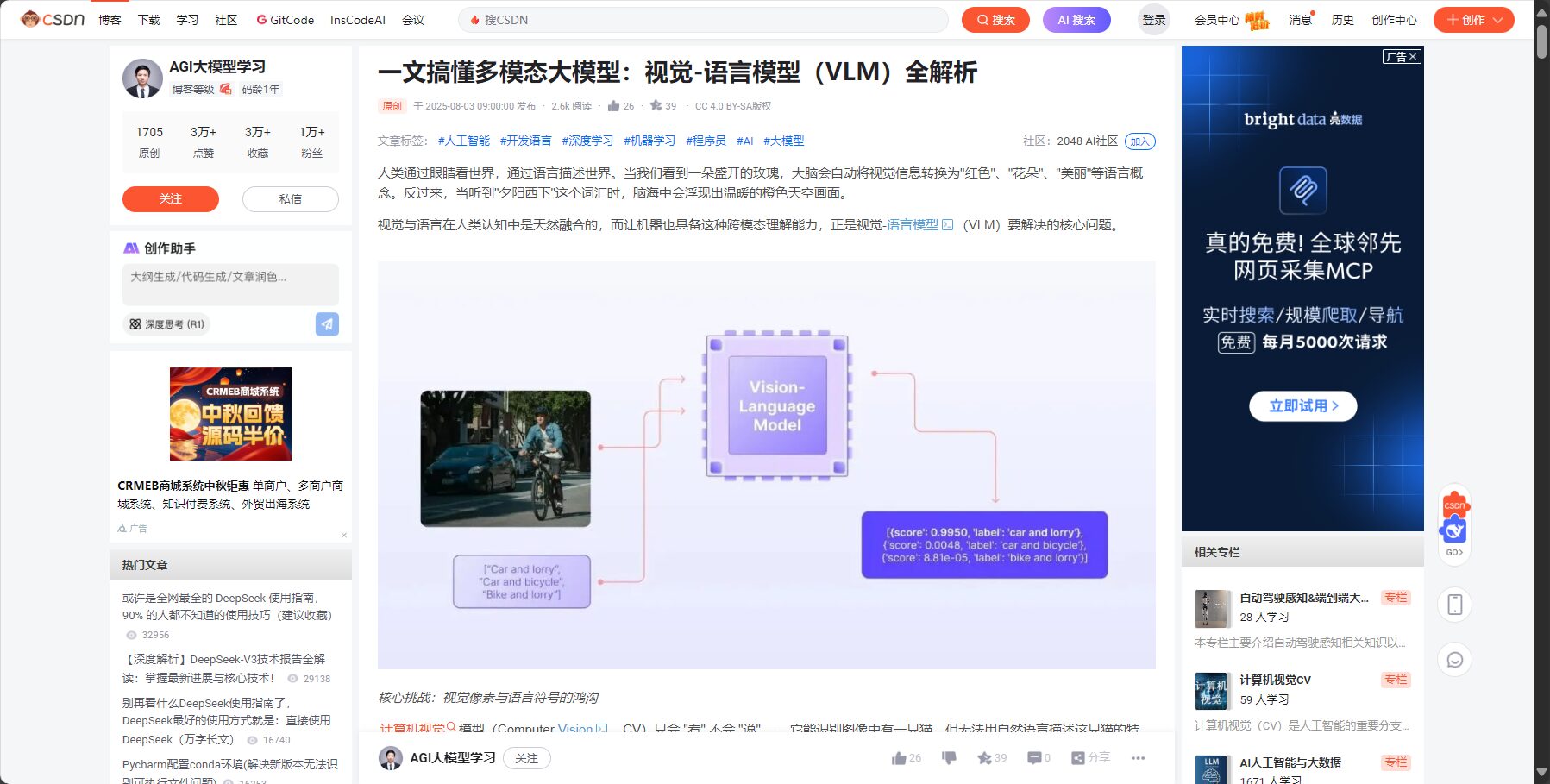
多模態大模型(Vision-Language Model, VLM)是可同時處理影像和文本,並產生自然語言輸出的AI系統。VLM具備強大「看圖說話」、指令理解生成及複雜推理能力,是推動智慧問答、文件質檢、視覺分析、OCR、法律/科研助理等場景的核心基礎設施。
VLM工作原理核心
- 視覺特徵提取器(ViT、CLIP等):將圖片、視訊像素轉為高層表徵。
- 語言模式主幹(Llama、Qwen等):對視覺表徵與文字融合,生成回應。
- 跨模態融合技術:如交叉注意力、序列統一編碼,實現視覺與文字深度耦合。

為什麼2025年VLM是產業焦點?
- 數據無界融合:文字、圖片、結構化資料場景無縫連動。
- 高價值應用驅動:醫療影像、報表分析、政企智慧辦公室等。
- 企業級部署:主流開源模型可靈活雲端/本地/端側部署,適合多種硬體。
7大最佳Vision-Language Model工具深度推薦
1. Gemini 2.5 Pro
開發商:Google DeepMind
特點:極致通用性,適合大規模高要求多模態場景;支援文字、圖片、影片、結構化多資料類型。
- 架構特徵:凍結SigLIP-ViT視覺塔+交叉注意力Transformer設計,任務切換靈活,推理極快。
- 文字視窗: 1萬~2萬tokens。
- 開放性:僅Google AI Studio或API調用,無開源版本。
- 適合場景:雲端原生SaaS、國際高安全需求。
- 應用程式亮點:Excel表解讀、多語種文件OCR、影片問答等。
2. GPT-5
開發商:OpenAI
特點:統一Transformer,圖片、音訊、文字輸入輸出一體融合。
- 架構:所有輸入當作序列處理,資訊流暢。
- 文字視窗:128k tokens。
- 開放性:閉源,僅OpenAI API。
- 適合場景:智慧客服、多模互動、即時圖片解析+音訊辨識。
3. Claude 4.1 Vision
開發商:Anthropic
特點:科學推理與OCR全球領先,處理超大PDF、結構化文件。
- 架構:重採樣ViT+輕量轉接器,推進長文檔OCR高精度。
- 文字視窗:200k tokens。
- 適合場景:學術科研、金融報告、法律資料分析。
- 應用程式亮點:PDF/表格智能處理等。

| 名稱 | 特色主攻 | 通用場景 | 長文支持 | OCR能力 | 互動能力 | 開放性 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 一般 | 强 | 强 | 强 | 極強 | 閉源 |
| GPT-5 | 融合 | 强 | 極強 | 强 | 極強 | 閉源 |
| Claude 4.1 Vision | PDF/OCR | 較強 | 極強 | 卓越 | 强 | 閉源 |
4. Qwen 2.5-VL-72B
開發商:阿里雲通義千問
特點:2025年最全能開源多模態大模型之一,長影片、任意解析度任務靈活。
- 架構:Window-Attention ViT+MRoPE+72B MoE,複雜任務高效處理。
- 文字視窗:128k tokens。
- 開放性:完全開源,可自建/用API呼叫。
- 適合場景:企業私有化文件AI、長文字/影片理解。
- 應用程式亮點:GPU算力節省,成本可控、長影片理解等。
Qwen-VL
5. Llama 4 Scout / Llama 4 Vision
開發商:Meta AI
特點:先進的混合專家多模架構,任務彈性強,開發者社群活躍。
- 架構:動態ViT補丁、多專家激活,支援高並發與水平擴展。
- 文字視窗:10k~100k tokens。
- 開放性:完全開源,API即開即用。
- 適合場景:客製化SaaS、自動辦公室助理、邊緣部署。
- 應用程式亮點:支援多語種、低延遲推理。
6. MiniCPM-V 8B
開發商:OpenBMB & 清華NLP
特點:端側多模態VLM新星,低算力流暢推理,適用IoT與行動端。
- 架構:端側專用簡化視覺塔+8B小語言模型。
- 文字視窗:32k+
- 開放性:完全開源。
- 適合場景:本地低功耗、工業應用。
7. CogVLM 17B
開發商:THUDM(清華)
特點:高品質預訓練,多跨模態測試SOTA,細粒度匹配、幻覺低。
- 架構:BLIP2-Qformer權重開放,易於自訂二次開發。
- 文字視窗:16k tokens。
- 開放性:完全開源。
- 適合場景:科研二次開發、圖片說話。
各大VLM工具適用場景一覽
| 主要場景 | 推薦VLM | 特色/說明 |
|---|---|---|
| 多語言長文檔+圖片 | Claude 3.7 Vision、Qwen 2.5-VL-72B | 極致長窗口,PDF/表格/法律稿件 |
| OCR+圖表 | Qwen 2.5-VL-72B、GPT-4o | 高精度結構化資料分析 |
| 影片/圖片理解 | Gemini 2.5 Pro、Llama 4 Vision | 複雜多模態任務 |
| 端側推理 | MiniCPM-V 8B | IoT、工業端側推理 |
| 客製化訓練 | CogVLM 17B、Llama 4 Vision | 私有資料增強 |
推薦API平台:可用Novita AI等平台直接API呼叫主流VLM模型。
產業趨勢與選型建議
* 為什麼開源VLM(Qwen 2.5-VL、Llama 4)會成中國市場主流?
- 政策合規:自主可控資料隱私,適配國內政策。
- 高性價比:大規模部署/本地推理,擺脫海外雲端依賴。
- 技術生態活躍:插件豐富,文件完善。
* 何時使用閉源大模型(GPT-4o, Gemini Pro)?
- 全球化需求:跨國公司/國際科研體驗AI極限。
- 極端大數據場景:超長上下文/多端即時同步。
* 未來趨勢
- 多模態VLM向輕量端側+雲端原生API並進
- 幻覺率控制/圖表理解/多語混合為主戰線
- API平台大勢,應用門檻持續降低
總結:2025年,VLM已進入開源與API融合、國產自研與國際閉源共進階段,所有產業都可依需求、預算、民營化或極致性能,從7大最佳工具中靈活選型。未來,多模態模型必將推動產品創新與生產力躍升。更多開源VLM體驗可見Novita AI模型庫。
© 版權聲明
文章版權歸作者所有,未經允許請勿轉載。
相關文章



暫無評論...