2025年,多模态大模型(VLM, Vision-Language Model)成为AI技术发展新高地。本文深度梳理全球7大VLM核心产品,对比开源闭源、技术路线、应用场景与本地化能力,全面解析其最新优劣势。文章适合开发者、企业决策人、科研工作者一站掌握AI视觉语言融合的最佳选型趋势与部署建议。
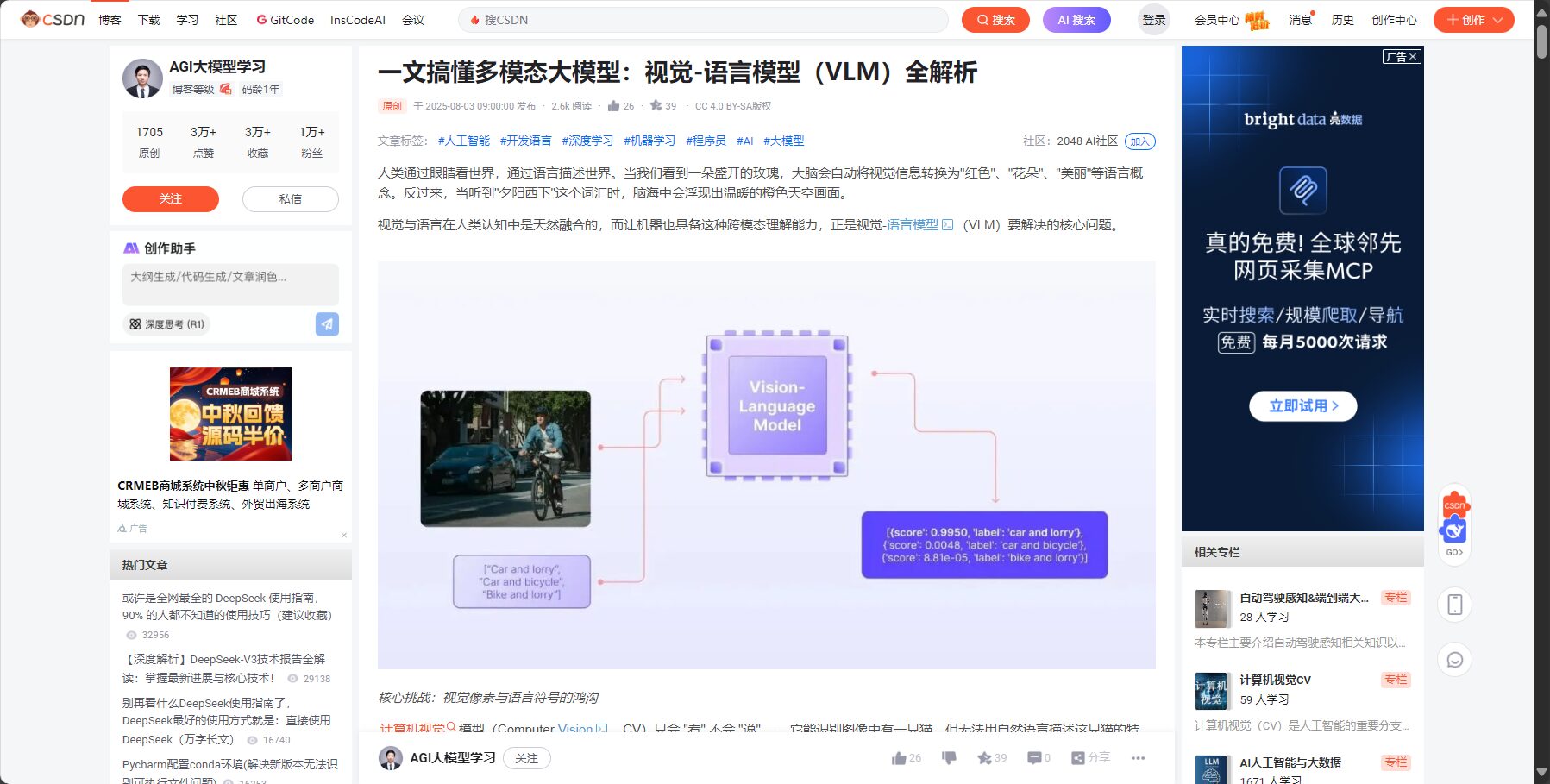
VLM 2025年度多模态大模型工具总览
在正式推荐前,先通过表格为读者呈现2025年最受关注的7大VLM工具特性一览:
| 名称 | 开源/闭源 | 关键特色 | 文本上下文窗口 | API/自托管 | 链接 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 闭源 | 通用多模态任务,极高灵活性 | 10k~20k | 官方平台 | Google AI Studio |
| GPT-5 | 闭源 | 统一Transformer,多模态高效融通 | 128k | 官方平台 | OpenAI |
| Claude 4.1 Vision | 闭源 | OCR/图表特化,强科学推理 | 200k | 官方平台 | Anthropic |
| Qwen 2.5-VL-72B | 开源 | 任意分辨率/长视频多模复杂任务 | 128k | API/自建 | Qwen-VL |
| Llama 4 Scout | 开源 | 混合专家机制,极高可扩展性 | 10k~100k | API/自建 | Llama 4 |
| MiniCPM-V 8B | 开源 | 超低参端侧推理,全面视频/图片理解 | 32k+ | API/自建 | MiniCPM-V |
| CogVLM 17B | 开源 | 微调SOTA性能,视觉+语言高分测试 | 16k | API/自建 | CogVLM |
表格说明:工具均支持现代多模态融合主流需求,部分工具可通过Novita AI等平台低成本API访问。
全球视角:vlm多模态AI模型定义与应用价值
什么是多模态大模型(VLM)?
多模态大模型(Vision-Language Model, VLM)是可同时处理图像和文本,并生成自然语言输出的AI系统。VLM具备强大“看图说话”、指令理解生成及复杂推理能力,是推动智能问答、文档质检、视觉分析、OCR、法律/科研助理等场景的核心基础设施。
VLM工作原理核心
- 视觉特征提取器(ViT、CLIP等):将图片、视频像素转为高层表征。
- 语言模型主干(Llama、Qwen等):对视觉表征与文本融合,生成回复。
- 跨模态融合技术:如交叉注意力、序列统一编码,实现视觉与文本深度耦合。

为什么2025年VLM是产业焦点?
- 数据无界融合:文本、图片、结构化数据场景无缝联动。
- 高价值应用驱动:医疗影像、报表分析、政企智能办公等。
- 企业级部署:主流开源模型可灵活云端/本地/端侧部署,适配多种硬件。
7大最佳Vision-Language Model工具深度推荐
1. Gemini 2.5 Pro
开发商:Google DeepMind
特点:极致通用性,适合大规模高要求多模态场景;支持文本、图片、视频、结构化多数据类型。
- 架构特征:冻结SigLIP-ViT视觉塔+交叉注意力Transformer设计,任务切换灵活,推理极快。
- 文本窗口: 1万~2万tokens。
- 开放性:仅Google AI Studio或API调用,无开源版本。
- 适合场景:云原生SaaS、国际高安全需求。
- 应用亮点:Excel表解读、多语种文档OCR、视频问答等。
2. GPT-5
开发商:OpenAI
特点:统一Transformer,图片、音频、文本输入输出一体融合。
- 架构:所有输入当作序列处理,信息流畅。
- 文本窗口:128k tokens。
- 开放性:闭源,仅OpenAI API。
- 适合场景:智能客服、多模交互、实时图片解析+音频识别。
3. Claude 4.1 Vision
开发商:Anthropic
特点:科学推理与OCR全球领先,处理超大PDF、结构化文件。
- 架构:重采样ViT+轻量适配器,推进长文档OCR高精度。
- 文本窗口:200k tokens。
- 适合场景:学术科研、金融报告、法律资料分析。
- 应用亮点:PDF/表格智能处理等。

| 名称 | 特色主攻 | 通用场景 | 长文支持 | OCR能力 | 交互能力 | 开放性 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 通用 | 强 | 强 | 强 | 极强 | 闭源 |
| GPT-5 | 融合 | 强 | 极强 | 强 | 极强 | 闭源 |
| Claude 4.1 Vision | PDF/OCR | 较强 | 极强 | 卓越 | 强 | 闭源 |
4. Qwen 2.5-VL-72B
开发商:阿里云通义千问
特点:2025年最全能开源多模态大模型之一,长视频、任意分辨率任务灵活。
- 架构:Window-Attention ViT+MRoPE+72B MoE,复杂任务高效处理。
- 文本窗口:128k tokens。
- 开放性:完全开源,可自建/用API调用。
- 适合场景:企业私有化文档AI、长文本/视频理解。
- 应用亮点:GPU算力节省,成本可控、长视频理解等。
Qwen-VL
5. Llama 4 Scout / Llama 4 Vision
开发商:Meta AI
特点:先进的混合专家多模架构,任务弹性强,开发者社区活跃。
- 架构:动态ViT补丁、多专家激活,支持高并发与水平扩展。
- 文本窗口:10k~100k tokens。
- 开放性:完全开源,API即开即用。
- 适合场景:定制SaaS、自动办公助手、边缘部署。
- 应用亮点:支持多语种、低延迟推理。
6. MiniCPM-V 8B
开发商:OpenBMB & 清华NLP
特点:端侧多模态VLM新星,低算力流畅推理,适用IoT与移动端。
- 架构:端侧专用简化视觉塔+8B小语言模型。
- 文本窗口:32k+
- 开放性:完全开源。
- 适合场景:本地低功耗、工业应用。
7. CogVLM 17B
开发商:THUDM(清华)
特点:高质量预训练,多跨模态测试SOTA,细粒度匹配、幻觉低。
- 架构:BLIP2-Qformer权重开放,易于自定义二次开发。
- 文本窗口:16k tokens。
- 开放性:完全开源。
- 适合场景:科研二次开发、图片说话。
各大VLM工具适用场景一览
| 主要场景 | 推荐VLM | 特色/说明 |
|---|---|---|
| 多语言长文档+图片 | Claude 3.7 Vision、Qwen 2.5-VL-72B | 极致长窗口,PDF/表格/法律稿件 |
| OCR+图表 | Qwen 2.5-VL-72B、GPT-4o | 高精度结构化数据分析 |
| 视频/图片理解 | Gemini 2.5 Pro、Llama 4 Vision | 复杂多模态任务 |
| 端侧推理 | MiniCPM-V 8B | IoT、工业端侧推理 |
| 定制训练 | CogVLM 17B、Llama 4 Vision | 私有数据增强 |
推荐API平台:可用Novita AI等平台直接API调用主流VLM模型。
行业趋势与选型建议
* 为什么开源VLM(Qwen 2.5-VL、Llama 4)成中国市场主流?
- 政策合规:自主可控数据隐私,适配国内政策。
- 高性价比:大规模部署/本地推理,摆脱海外云依赖。
- 技术生态活跃:插件丰富,文档完善。
* 何时用闭源大模型(GPT-4o, Gemini Pro)?
- 全球化需求:跨国公司/国际科研体验AI极限。
- 极端大数据场景:超长上下文/多端实时同步。
* 未来趋势
- 多模态VLM向轻量端侧+云原生API并进
- 幻觉率控制/图表理解/多语混合为主战线
- API平台大势,应用门槛持续降低
总结:2025年,VLM已进入开源与API融合、国产自研与国际闭源共进阶段,所有行业都可根据需求、预算、私有化还是极致性能,从7大最佳工具中灵活选型。未来,多模态模型必将推动产品创新与生产力跃升。更多开源VLM体验可见Novita AI模型库。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...