過擬合(Overfitting)是當前機器學習領域的核心難題,意指模型過度貼合訓練數據,降低對新資料預測能力。隨著AI在醫療、金融、電商等產業日益普及,過擬合不僅影響決策準確,嚴重會帶來重大風險。
本篇將詳析過擬合徵兆、成因、檢測方法,並系統整理五大有效防治對策(如正則化、交叉驗證、模型簡化、數據擴增、提前停止),同時推薦主流AI工具,助您牢牢掌控模型泛化能力!
什麼是過擬合?AI模型效能的核心威脅
在機器學習與人工智慧領域,過擬合(Overfitting)是專業人員反覆警覺的重要關鍵詞。當一個模型太過貼合訓練資料細節,失去對新資料的泛化能力,就會造成現實應用中預測失效。例如,訓練數據準確率高達95%,但面對新環境時預測表現急遽下滑。
隨著AI應用於醫療、金融、電商、製造業,過擬合風險會讓企業誤判局勢,產出錯誤決策,甚至造成安全及合規問題。
過擬合現象觀察與成因分析
過擬合的徵兆與模型評估
- 訓練集表現極佳、驗證集/測試集表現明顯變差
- 新數據預測差錯顯著增加
- 模型對雜訊、例外情形非常敏感
| 過擬合現象 | 描述 |
|---|---|
| 訓練準確率偏高 | 訓練集接近完美預測 |
| 測試準確率低 | 新資料預測較差 |
| 權重參數過大 | 大量參數學習資料細節 |
| 模型過於複雜 | 失去泛化、只記雜訊 |
成因解析
- 模型複雜度過高:如深層神經網絡、過多參數
- 數據量或多樣性不足
- 標註有誤或資料雜訊過多
- 訓練迭代過長,記住細枝末節
檢測過擬合的常見方法
| 檢測方法 | 說明 |
|---|---|
| 準確率/損失對比 | 訓練集vs測試集落差5-10%為警示 |
| K折交叉驗證 | 多輪數據分割驗證一致性 |
| 學習曲線觀察 | 訓練與驗證表現是否同步成長且間隔縮小 |

機器學習如何避免與緩解過擬合?5大實用策略一次看
過擬合預防需從資料前處理、模型設計、訓練監控到結果評估全流程考量:
| 對策 | 核心機制 | 推薦工具/鏈接 |
|---|---|---|
| 1. 正則化 | 為損失函數增加懲罰項 | scikit-learn Lasso/Ridge; Keras Regularizers |
| 2. 交叉驗證 | 多組數據驗證結果穩定性 | scikit-learn Cross Validation |
| 3. 模型簡化 | 約束模型結構複雜度 | sklearn DecisionTree 限 max_depth |
| 4. 增加數據 | 豐富樣本數量與型態 | Google Data Augmentation API、Albumentations |
| 5. 提前停止 | 自動判斷停止訓練最佳時機 | Keras EarlyStopping |
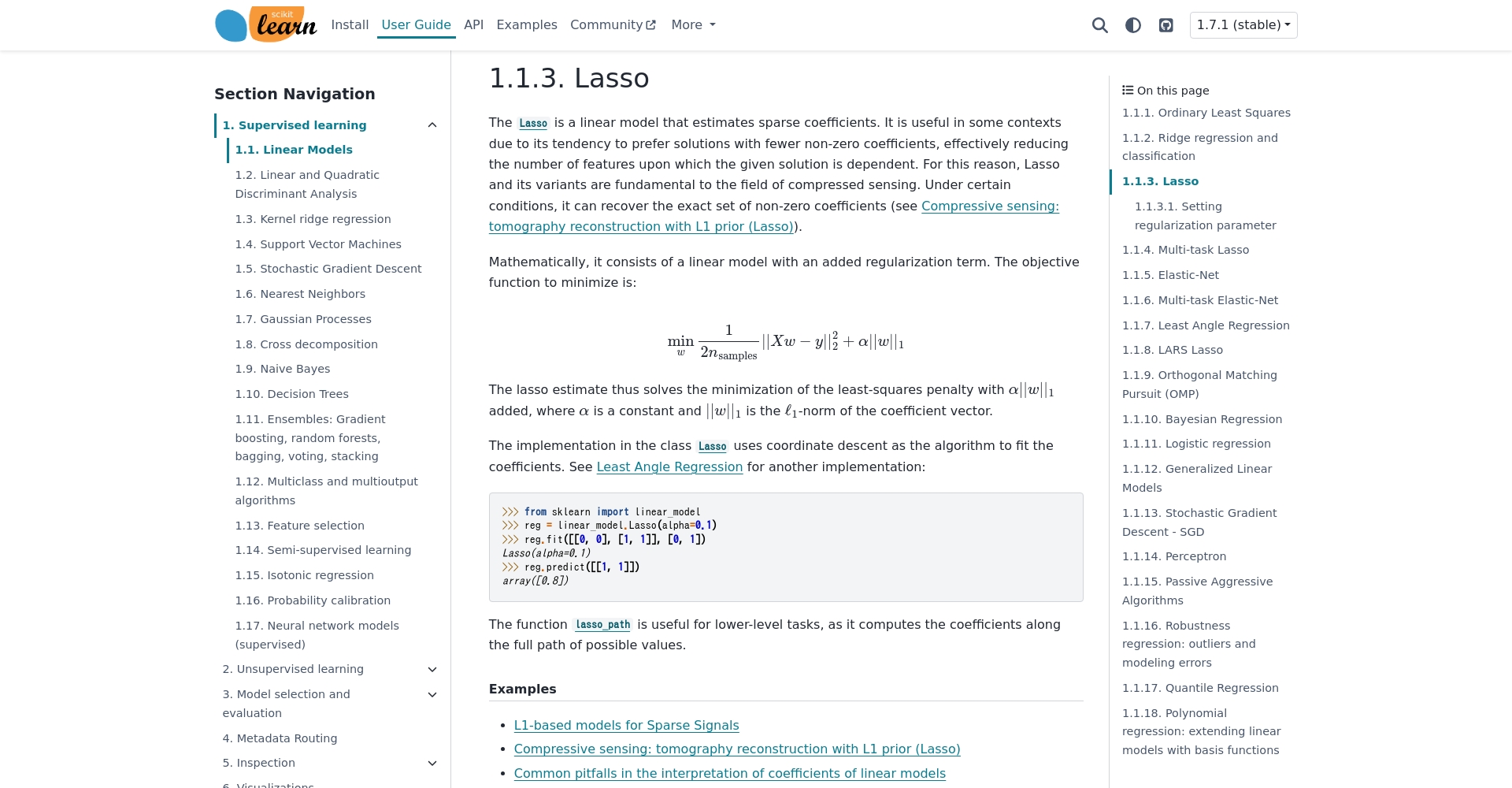
過擬合防治重點措施詳解
正則化(Regularization)——AI最佳無痛方案
引入「懲罰項」防止權重極端,提高泛化能力。常見方式有:
- L1(Lasso)——自動剃除冗餘特徵
- L2(Ridge)——抑制所有權重,使模型平滑
- Elastic Net——兩種方式綜合
專案實例:使用 scikit-learn Lasso、Ridge、Keras 正則器可顯著減緩模型過擬合。
交叉驗證(Cross-validation)——穩定泛化驗證利器
- K折交叉驗證(K-Fold):分多折重複驗證結果更可靠
- 留一法(LOOCV):少量數據首選
- 分層抽樣:資料類別分布保持一致
可用 scikit-learn 的 cross_val_score 或 PyCaret、AutoML自動應用。
模型簡化與特徵選擇——控制結構杜絕過擬合
- 降低模型複雜度(如減少神經網絡層數、限制深度)
- 特徵選擇剃除無用維度(如L1范式)
推薦:sklearn Feature Selection、ML.NET自動特徵精簡
數據量擴增與質量管理
豐富數據數量和多樣性,是本質解法。
- 影像:鏡射、旋轉、調色等數據增強
- 文本:同義替換、段落重組
工具:Albumentations、TensorFlow Data Augmentation
提前停止(Early Stopping)與 Dropout——訓練過程動態監控
監控驗證表現,一旦最佳點出現自動停機。Dropout則是每輪隨機屏蔽部分神經元,增強魯棒性。配合 PyCaret、Keras 等平台,易於實現。
實戰常用AI工具、平台推薦
| 工具/平台 | 主要特色 | 應用方向 |
|---|---|---|
| scikit-learn | 各種正則化、交叉驗證、特徵篩選 | 傳統機器學習 |
| Keras & TensorFlow | EarlyStopping、Dropout | 深度學習建模 |
| PyCaret | 自動化訓練、交叉驗證 | 資料科學全流程 |
| AutoML | 自動調參與早停、資料增強 | 雲端AI服務 |
過擬合相關常見疑問解答區
為何只看訓練集準確率容易落入過擬合陷阱?
訓練集準確率高,可能只是模型『記住』資料細節甚至噪音,不代表能有效預測新情境。若測試資料表現顯著下滑,即要高度警覺過擬合。
如何判斷是模型過於複雜,還是資料太少?
比對學習曲線,若資料量提升後測試準確率大幅進步,說明資料不夠。若資料夠多仍有過擬合,則須簡化模型。
實際應如何著手?
先嘗試加正則化/Dropout,再做交叉驗證、提前停止;如數據集偏小,再考慮資料增強。
產業應用案例——防患未然
金融業:日本MUFG銀行導入AutoML自動早停、正則化,預防信貸評估模型過擬合,成功降低誤判風險。
醫療影像診斷:Google Health團隊配合資料增強與Albumentations自動多管道擴增,顯著提升新病照泛化效果。
AI從業者應全流程把控過擬合問題,並擅用自動化AI工具平台,實現穩定高效的智慧應用!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...